Anatomy of an Agentic Analytics System: Inside the Multi-Step Reasoning Loop

Anatomy of an Agentic Analytics System: Inside the Multi-Step Reasoning Loop
When someone asks "how does an agentic analytics system work," the usual answer is "it uses AI to answer questions." That's accurate in the way that "a jet engine uses combustion to fly" is accurate : technically true, completely insufficient for understanding what's actually happening.
This post opens the hood on the agentic analytics architecture: what the reasoning loop does, how the LLM uses tools to execute queries, how the agent handles errors and refines its approach, and what makes the difference between an agent that produces useful answers and one that confidently produces wrong ones.
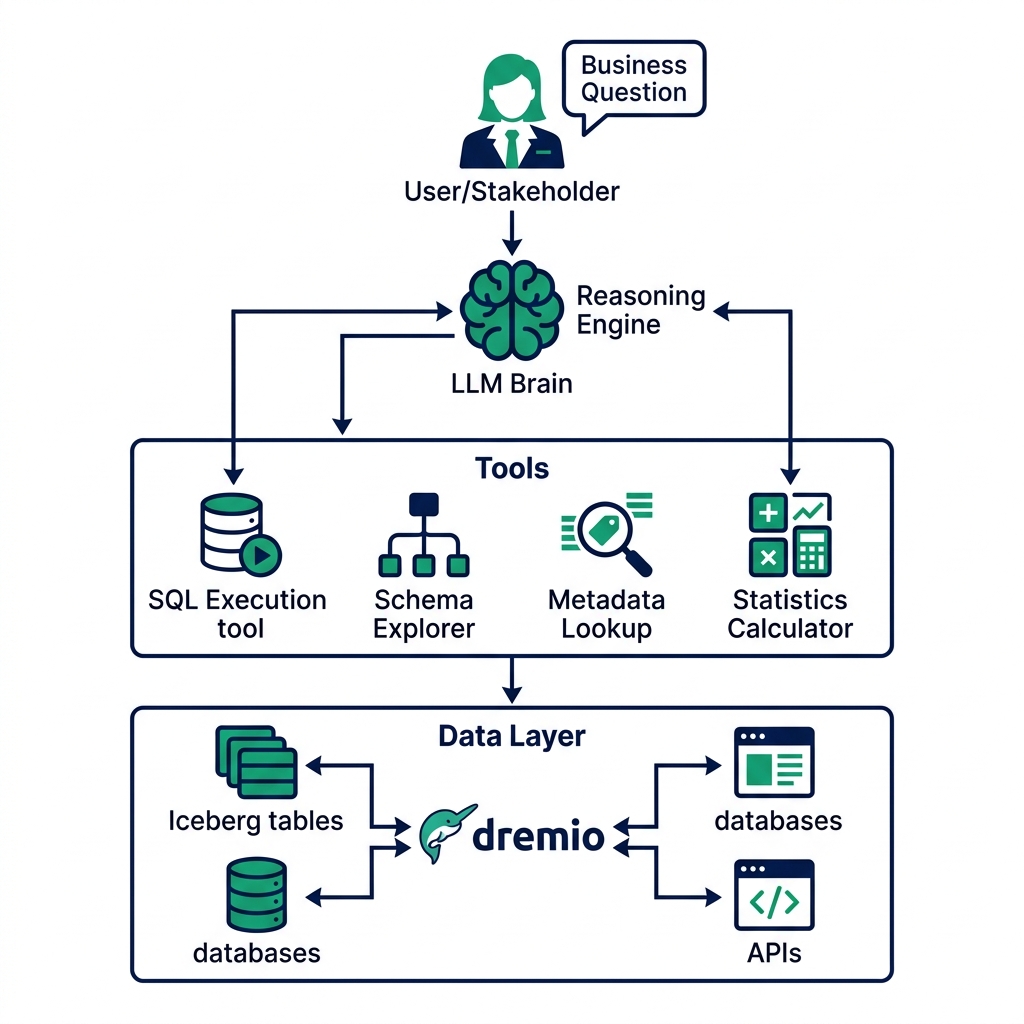
The ReAct Loop: Reason, Act, Observe
The core pattern in modern agentic analytics systems is ReAct: Reasoning + Acting. The loop runs in three phases that repeat until the agent satisfies the goal or determines it can't.
Reasoning: The LLM analyzes the current state : the original goal, any results from previous query steps, any errors encountered, and determines what to do next. This produces a structured "thought": a description of the hypothesis to test, what data is needed, and which tool to use.
Acting: The agent invokes a tool. For analytics, the primary tools are SQL execution and schema exploration. The agent generates a SQL query and sends it to the query engine through a structured function call. The function call is typed and validated : not free-form text that gets parsed, but a defined schema with query text, target catalog, and execution parameters.
Observing: The system captures the tool's output and returns it to the agent. For a successful SQL query, this is the result set. For a failed query, this is the error message and any database context available. The agent reads the observation, updates its understanding of the problem, and decides whether to continue, retry with a corrected approach, or declare the investigation complete.
The loop runs sequentially: one thought, one action, one observation. No parallel reasoning within a single loop iteration. Complex investigations may run 10–20 iterations before reaching a conclusion.
Tool Access Design: What the Agent Can Do
The quality of an agentic analytics system depends heavily on which tools the agent has access to and how they're defined.
Schema exploration tools let the agent discover tables, columns, data types, and relationships without prior knowledge of the schema. The agent can call list_schemas(), describe_table(table_name), or get_column_statistics(table, column) before writing any SQL. This is essential for schemas the agent hasn't encountered before.
SQL execution tools run queries against the data platform and return results. The tool definition should include the max result size (to prevent returning millions of rows to the agent's context), timeout limits, and which catalog and schema to query.
Metadata tools access documentation in the semantic layer: wiki descriptions, column labels, metric definitions. When the agent is confused about what a column means, it can query the metadata tool for the documented definition before guessing. Dremio's semantic layer exposes this metadata through its MCP server, making it available to any agent that connects.
Calculation tools handle statistical operations that SQL handles poorly : rolling averages, percentile calculations, contribution analysis, variance decomposition. The agent can call these for analysis steps that don't map cleanly to standard SQL.
Schema Exploration in Practice
When an agentic system encounters a new question about a schema it hasn't analyzed before, it starts with exploration rather than querying.
A well-designed agent begins by listing available schemas, then listing tables in the relevant schema, then describing the tables most likely to contain the relevant data, then examining column statistics to understand data ranges and null rates. This typically takes 3–5 tool calls before the agent writes its first analytical query.
This exploration step is expensive : it adds 5–10 seconds to the response time. But it prevents the agent from writing SQL that references non-existent columns or joins on mismatched types. The alternative, skipping exploration and trusting the model's general knowledge : produces errors on real schemas that don't match the training distribution.
Semantic layers reduce the exploration cost significantly. When table and column documentation is rich and accurate, the agent can often go straight to the analytical query without full schema exploration, because the metadata provides the context it would otherwise need to discover empirically.
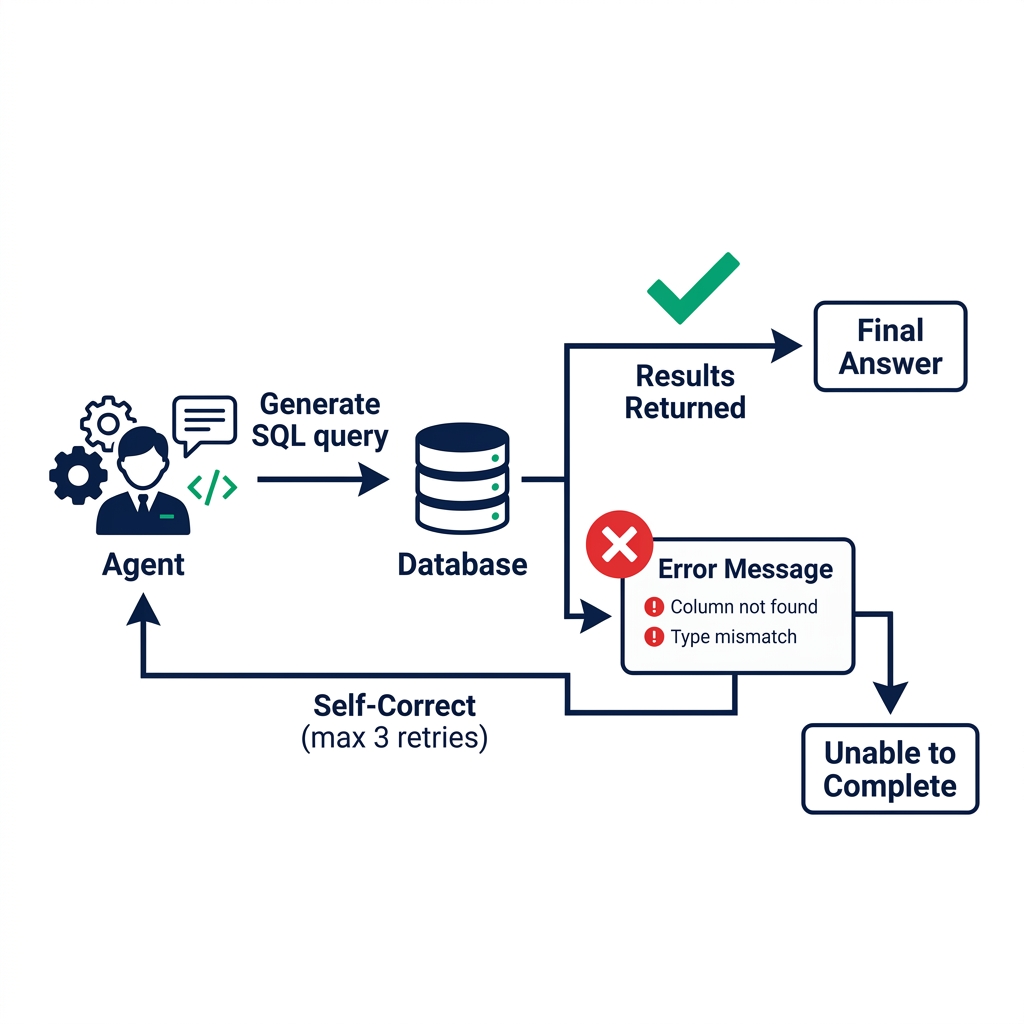
Self-Correction: How the Agent Handles Errors
The most practically important capability of a multi-step reasoning loop is self-correction. Real analytical environments are messy: data types are inconsistent, column names contain encoding errors, some tables have null primary keys, referenced metrics haven't been computed for the current period yet.
When a SQL query returns an error, the agent's observation is the error message and any database context included in the response. A well-designed agent reads the error carefully and generates a corrected query on the retry.
Common error patterns and their corrections:
| Error | Agent Corrective Action |
|---|---|
| Column not found | Re-explore table schema, find correct column name |
| Type mismatch in JOIN | Add CAST to the appropriate column |
| Division by zero | Add a CASE statement or filter before dividing |
| No results returned | Relax filter conditions, verify date range |
| Result too large | Add LIMIT, aggregate, or narrow the filter |
Self-correction doesn't work indefinitely. Agents should have a maximum retry count per step (typically 3) and a global iteration limit (typically 20). If the agent can't execute a valid query after 3 retries, it should return a specific "unable to complete" response with the last error message, not hallucinate an answer.
Multi-Agent Systems for Complex Analysis
Single-agent loops handle most analytical investigations. For complex, multi-domain analyses that require different types of expertise, multi-agent architectures distribute the work.
A common pattern: an orchestrator agent breaks the high-level goal into sub-goals and delegates each to a specialized sub-agent. A "Data Retrieval" agent handles schema exploration and raw data extraction. A "SQL Writer" agent generates queries based on specifications from the Data Retrieval agent. A "Report Synthesizer" agent assembles the findings into a structured narrative.
Each agent's output becomes input for the next. The orchestrator manages sequencing, handles failures, and assembles the final result.
The downside of multi-agent architectures is latency. Each agent handoff adds network overhead and reasoning time. For questions that need an answer in under 30 seconds, a single well-designed agent with good tool access is usually faster than a multi-agent pipeline.
What Determines Agent Quality
The accuracy and reliability of an agentic analytics system depend on three things, in roughly equal measure:
Semantic context quality: An agent working with rich, accurate metadata produces correct SQL. An agent guessing at column meanings produces plausible-but-wrong SQL. The investment in documentation pays directly in agent accuracy.
LLM capability: Larger, more capable models handle complex multi-step reasoning better than smaller models. The model needs to understand SQL syntax, database concepts, and business logic simultaneously.
Tool design: Tools that return structured, informative outputs (including error context) give the agent what it needs to self-correct. Tools that return raw errors without context force the agent to guess what went wrong.
Dremio's MCP server exposes the full semantic layer to external agents, providing the context that makes agent outputs reliable.
Try Dremio Cloud free for 30 days and connect your own AI agent to a production-grade agentic analytics platform.