The Death of the Data Swamp: Establishing Governance in Your 2026 Data Lakehouse

The Death of the Data Swamp: Establishing Governance in Your 2026 Data Lakehouse
A data lake becomes a data swamp when teams stop trusting it. Tables accumulate with no clear owners. Column names mean different things in different tables. Schema changes break downstream jobs silently. No one knows which version of "revenue" is correct.
Lakehouses solve many of the technical problems that created swamps : ACID transactions, schema evolution controls, time travel, but they don't solve the governance problem automatically. You still need active stewardship, clear metadata standards, and the tooling to enforce them.
This post covers the practical governance model for a modern data lakehouse in 2026.
Why Lakehouses Still Become Swamps
The file-based nature of data lakehouses makes it easy to land data without structure. An engineer drops a Parquet file in a directory, registers it as an Iceberg table, and it's queryable. The data is there, but without documentation, access controls, or schema ownership, no one knows if it's correct or who maintains it.
The three failure modes:
No schema ownership: When a table's schema changes : a column renamed, a type widened, a partition scheme updated, there's no one accountable for notifying downstream consumers. Broken pipelines are discovered by business users who find blank cells in their dashboards, not by the data team that made the change.
Metric inconsistency: Multiple teams define the same concept differently. Finance calculates "monthly active users" as users with at least one session in the month. Marketing calculates it as users who opened an email or logged in. Both are plausible. Neither is documented. Executives see different numbers and lose confidence in the platform.
Access without accountability: Data lands in the lake, and access permissions are permissive by default. Analysts find useful tables and start building reports on them. No one notices that some of those tables contain unmasked PII or that the data is from an unvalidated source.
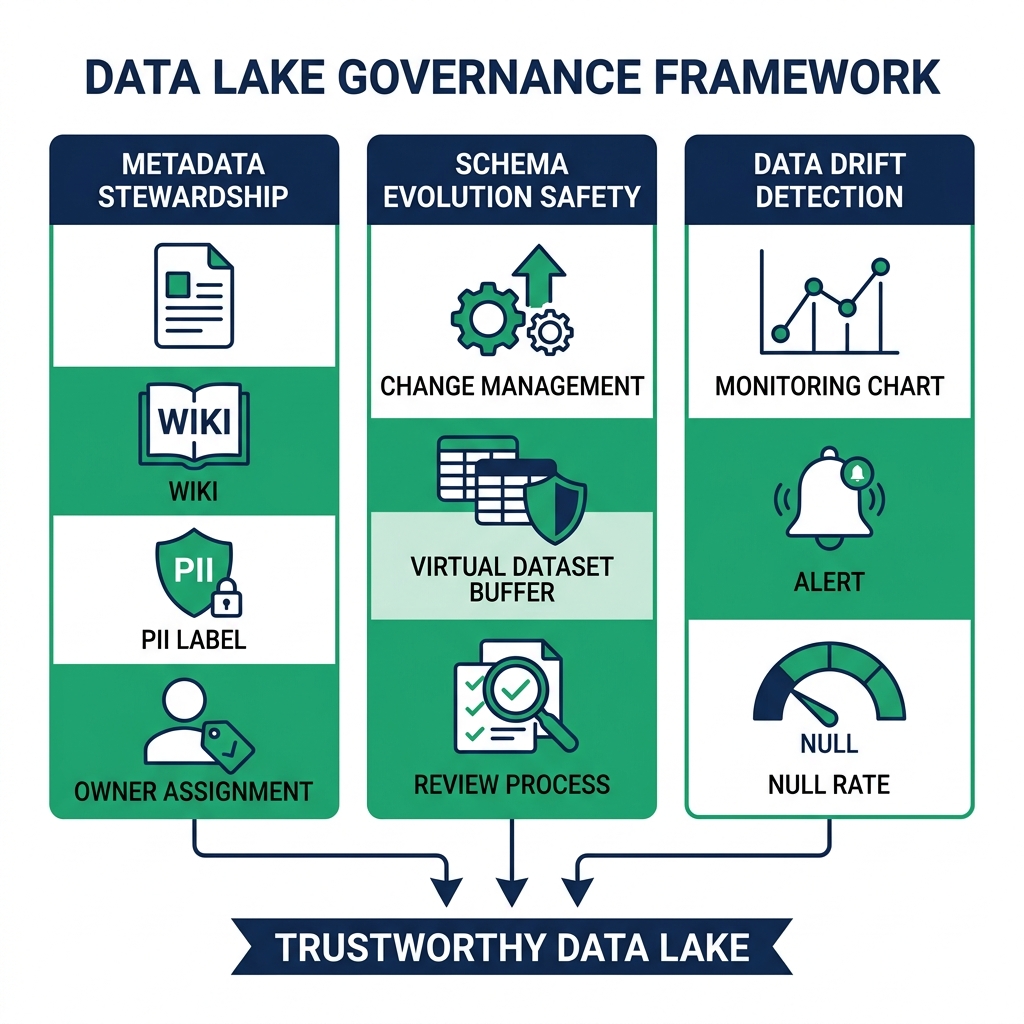
The Three Components of Active Governance
Active governance requires three things working together: metadata stewardship, schema evolution safety, and data drift detection.
Metadata Stewardship
Every table in your lakehouse should have a documented owner, a description of its contents, classifications for sensitive columns, and a record of which downstream processes depend on it.
Dremio's semantic layer makes this executable. Wikis attach human-written (or AI-generated) documentation directly to datasets and columns. Labels classify columns as PII, financial, operational, or other categories. This metadata lives in the catalog alongside the schema : it's not in a separate documentation system that goes out of date.
The AI-generated metadata feature in Dremio samples a table's schema and contents, then generates wiki descriptions for each column. A human steward reviews and approves. This reduces the labor cost of documentation enough that teams actually do it, rather than treating metadata as optional.
Assign clear ownership before a table reaches production. A table without an owner is a table without accountability. Ownership should be at the team level, not the individual level : individual owners leave organizations; teams don't.
Schema Evolution Safety
Iceberg's schema evolution rules prevent the most destructive changes from happening silently. Adding a column is always safe. Dropping a column requires that no downstream manifest references it. Widening a type (int to long) is safe. Narrowing a type is not allowed.
But schema evolution rules only prevent accidental damage at the format level. They don't prevent business-logic breaks : a column that's renamed from revenue_usd to gross_revenue_usd is technically valid but breaks every downstream query that references the old name.
Use Dremio's virtual datasets as the stable contract layer. Build views on top of raw Iceberg tables. Downstream consumers query the views, not the tables. When a column changes in the underlying table, update the view to preserve the old name as an alias. Consumers are unaffected.
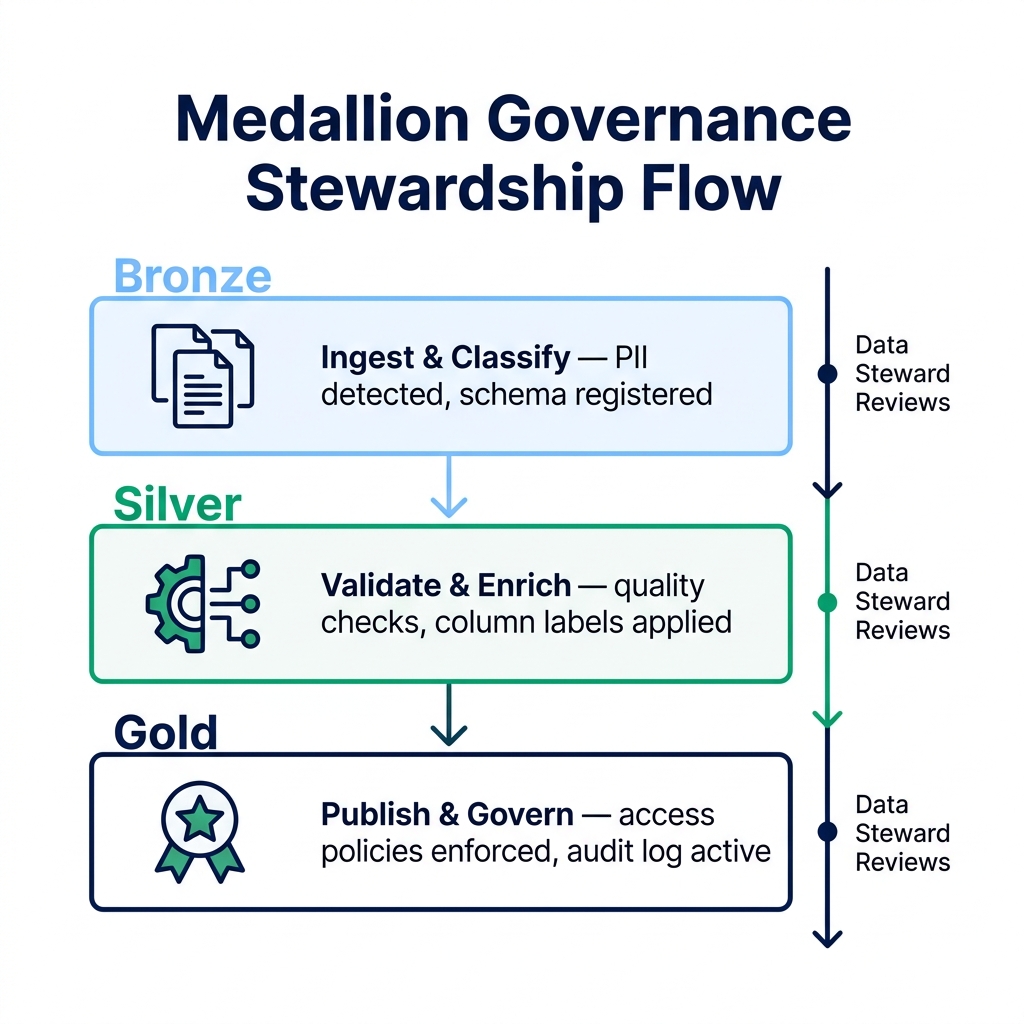
The medallion architecture formalizes this: Bronze tables match raw source data and change frequently. Silver views translate Bronze schemas into stable business terms. Gold views serve specific applications. Changes in Bronze propagate through Silver only after explicit review.
Data Drift Detection
Data drift is when the actual data in a table starts diverging from what the table is supposed to contain. A sensor stops sending readings and the column fills with nulls. A source system changes its encoding and string fields start arriving with unexpected characters. A calculation pipeline changes its logic and historical aggregates shift.
Drift doesn't trigger errors : it produces wrong results silently.
The minimum viable drift detection setup:
- Monitor null rates per column in each daily batch. Alert when a column's null rate increases by more than 5% from its 30-day average.
- Monitor record counts per partition. Alert when a partition receives significantly fewer records than historical average.
- Run automated reconciliation queries that compare key aggregates (row counts, sums of financial columns) against the previous period.
Dremio's AI SQL functions can automate some of this. AI_CLASSIFY can flag rows that don't match expected patterns. AI_COMPLETE can summarize anomaly reports into human-readable alerts. These aren't replacements for purpose-built data quality monitoring tools, but they can catch obvious drift quickly.
Catalog-Level Enforcement Points
Governance needs enforcement, not just documentation. The three enforcement points:
Catalog registration requirement: Tables can't be queried until they have a registered owner and a non-empty description. This can be enforced through catalog policies in Dremio's Open Catalog : tables without metadata fail the registration check.
Access request workflow: Default access to new tables is read-restricted. Access grants require approval from the table owner. This prevents the "permissive by default" pattern that turns lakehouses into swamps.
Breaking change review: Schema changes to production tables go through a review process. The review includes an impact analysis: which virtual datasets, reports, and pipelines reference the changed table or column.
These processes require organizational discipline in addition to tooling. The tooling provides the audit log and the enforcement mechanism. The organizational process provides the review and approval step.
Where to Start
If you're running an existing lakehouse that has accumulated ungoverned tables, the recovery path is:
- Audit: Generate a list of all tables, their last modified date, their query frequency, and whether they have a documented owner.
- Triage: Mark tables that have no owner and no queries in the last 90 days as candidates for deprecation. Tables with active queries get an owner assigned retroactively.
- Document: Use Dremio's AI metadata generation to create wiki drafts for active tables. Have a human review and approve each one.
- Enforce: Set the catalog registration requirement and access control policies going forward. Grandfather existing tables with a deadline for compliance.
Building governance from scratch into a new lakehouse is simpler than fixing an existing one. Set the standards before the first table lands.
Try Dremio Cloud free for 30 days and start with a governed, documented catalog from day one.