How Apache Iceberg Resolves the Hybrid-Cloud Challenge in Heavily Regulated Markets

How Apache Iceberg Resolves the Hybrid-Cloud Challenge in Heavily Regulated Markets
Financial institutions in Japan, Germany, and similar regulated markets face a specific architectural problem. Their regulators require sensitive data to stay on-premises or within a defined geographic boundary. Their data teams want cloud-scale analytics. Those two requirements pull in opposite directions, and proprietary cloud warehouses make the conflict worse.
Apache Iceberg resolves this by separating what the data is stored as from where it is stored and which engine queries it. That separation gives regulated enterprises a path to hybrid-cloud analytics that doesn't compromise data residency compliance.
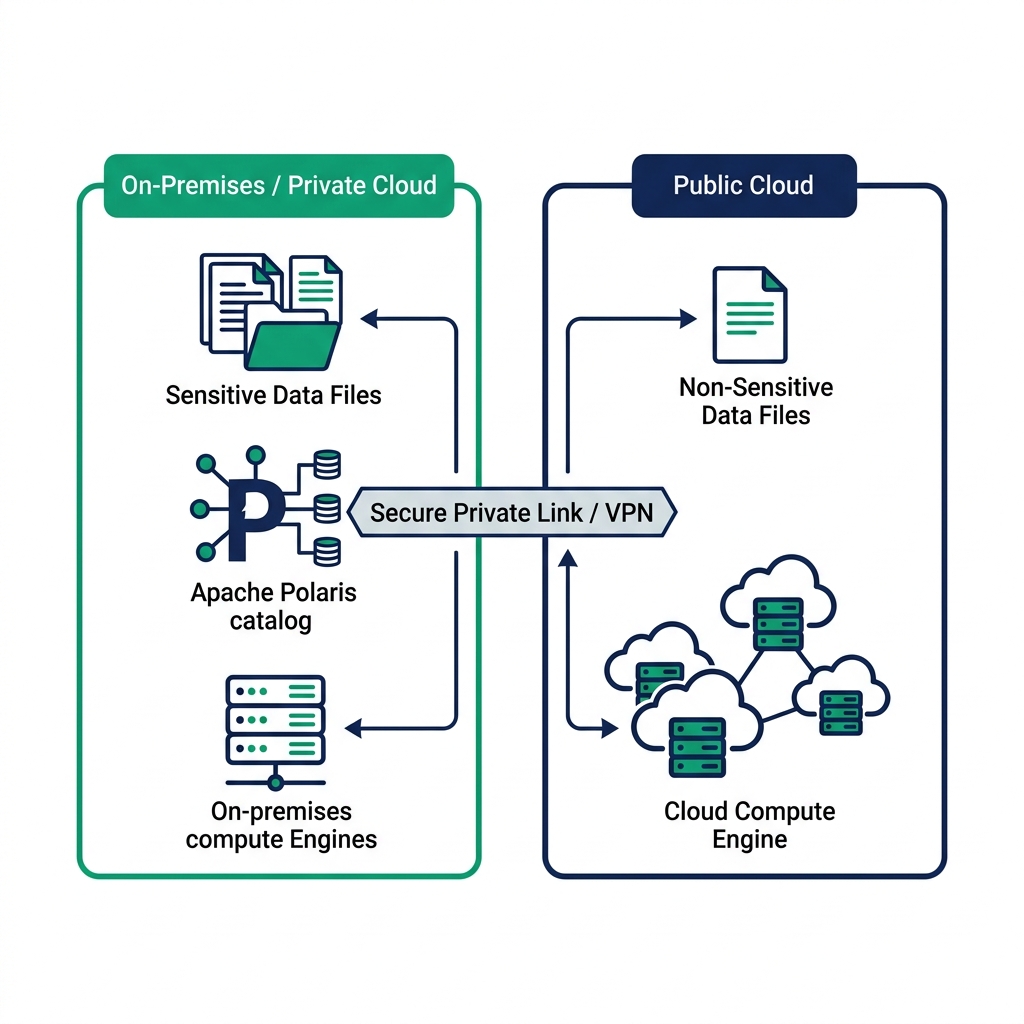
The Data Residency Problem in Regulated Markets
Japan's Act on the Protection of Personal Information (APPI) and the Financial Services Agency (FSA) guidelines restrict where personal and financial data can be processed. Germany's BAFIN guidelines and the EU's GDPR impose similar constraints. These regulations don't just limit storage : in some cases, they constrain which compute resources can access sensitive rows.
Proprietary cloud warehouses create a compliance problem because they bundle storage and compute into a single hosted system. Your data goes into their infrastructure. You may have some region selection options, but the catalog, access control, and audit logs all run in the vendor's cloud. For regulated Japanese institutions, that means customer data flowing through infrastructure they don't control.
The result is a two-system architecture that most regulated enterprises default to: an on-premises system for sensitive data and a cloud warehouse for analytical workloads on non-sensitive data. Those systems require ETL to synchronize them, which adds cost, latency, and yet another point where data moves across boundaries.
How Apache Iceberg Changes the Architecture
Iceberg tables store their data in Parquet files on object storage. That storage can be on-premises (using S3-compatible systems like MinIO or Ceph), in a private cloud, or in a public cloud region that meets residency requirements. The Iceberg table format itself doesn't dictate where the storage lives.
The Iceberg catalog : which tracks table metadata, schema, and file locations, is also storage-agnostic. You can run an open-source Iceberg REST catalog entirely within your own data center. Compute engines connect to that catalog to discover tables and get file locations. No data ever leaves your controlled environment unless you explicitly configure an engine to move it.
This creates an architecture where:
- Sensitive data stays on-premises in your own object storage
- An on-premises or private-cloud Iceberg catalog manages metadata
- Analytical engines can be on-premises or in a private cloud connected by VPN
- Non-sensitive workloads can run on public cloud compute engines
All of these engines read the same Iceberg table format. You don't need separate data models or ETL jobs to maintain different copies.
Apache Polaris as the Cross-Environment Catalog
Apache Polaris is an open-source implementation of the Iceberg REST catalog specification. Because it follows an open standard, any Iceberg-compatible engine (Spark, Trino, Flink, Dremio) can connect to it without vendor-specific connectors.
For regulated environments, Polaris matters for two reasons.
First, you can run it yourself. Unlike vendor-managed catalogs that live in the vendor's cloud, a self-hosted Polaris instance stays within your infrastructure boundary. You control the authentication, the access logs, and the retention of catalog metadata.
Second, Polaris provides role-based access control (RBAC) at the catalog level with credential vending. When an engine needs to read a table, Polaris issues short-lived, scoped credentials. The engine only gets access to the specific storage paths its role permits. Even if a compute cluster in a less-restricted zone connects to the catalog, Polaris controls which data files it can actually read.
Dremio's Open Catalog extends this model by combining Apache Polaris with federated source connections. A Dremio deployment in a controlled environment can serve as the authorized access point for regulated Iceberg tables, enforcing fine-grained access control (FGAC) including row-level filtering and column masking through user-defined functions (UDFs). External engines in less-sensitive zones connect through Dremio, which enforces the governance policies consistently.
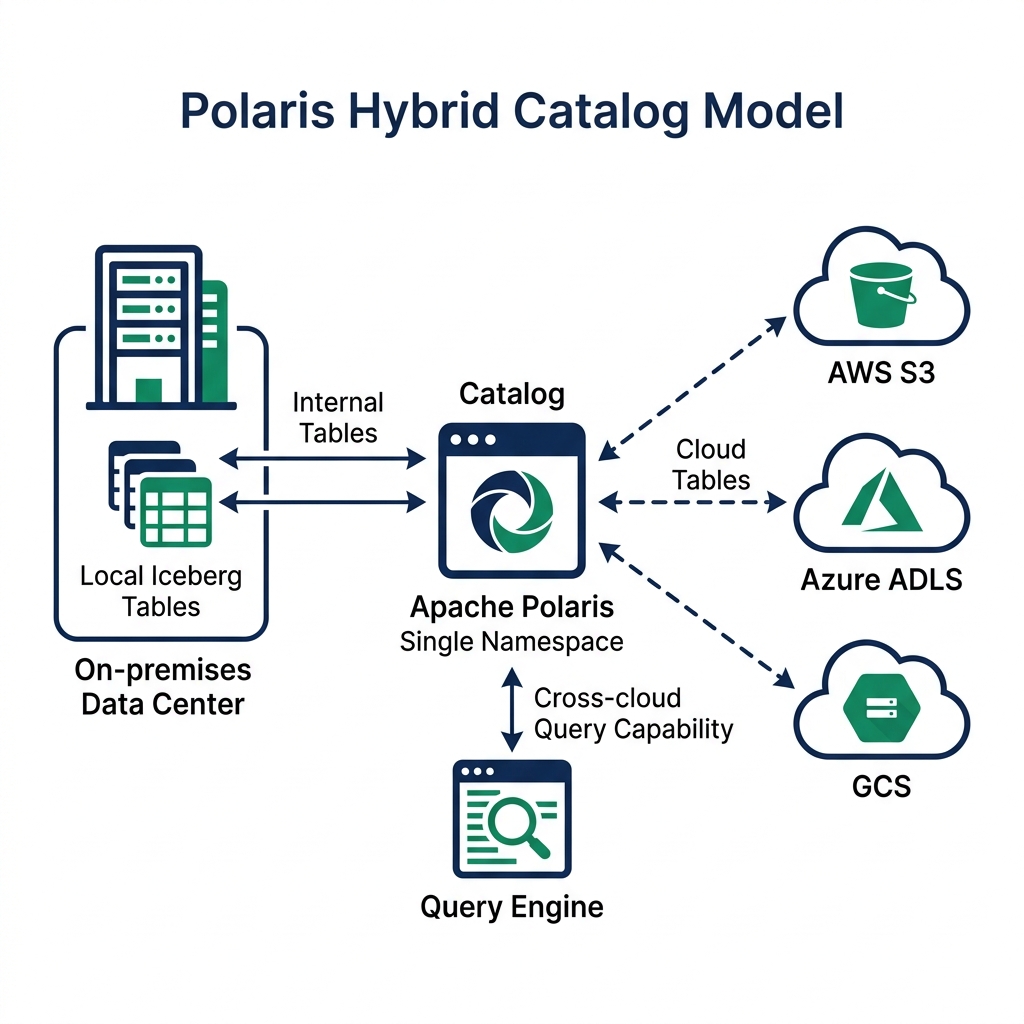
Cross-Catalog Synchronization for Mixed Workloads
Not all data in a regulated institution is sensitive. General ledger aggregates, anonymized customer segments, and macroeconomic indicators often carry no residency restrictions. Those datasets can live in a public cloud Iceberg catalog and be queried by cloud-based compute without any compliance concern.
The challenge is joining sensitive on-premises tables with non-sensitive cloud tables in a single query. Iceberg's open catalog standard makes this possible through catalog federation. A query engine connected to both catalogs can reference tables from each in the same SQL statement. The engine plans the query, reads from each location according to the credentials it holds, and assembles the result.
Dremio's query federation handles this pattern directly. It connects to multiple catalogs : one on-premises, one in the cloud, and presents them in a unified namespace. An analyst writes a single SQL query. Dremio handles the cross-environment execution, applying access control from each catalog at the appropriate step.
The on-premises data never moves to the cloud. The cloud data never gets pulled into the on-premises system unnecessarily. Predicate pushdown filters data at the source before it crosses the network boundary.
Practical Implementation Considerations
Running a hybrid Iceberg deployment in a regulated environment requires attention to a few operational details.
Network segmentation: The connection between on-premises infrastructure and cloud compute environments should go through a dedicated private link or VPN, not the public internet. Iceberg metadata and credential vending traffic is small, but it carries authorization information that must be protected in transit.
Audit trails: Catalog-level audit logs from Polaris and engine-level query logs must both be retained within the compliance boundary. If your regulation requires a 7-year audit trail, your catalog logs need the same retention policy as your transaction records.
Encryption: Iceberg v3 adds built-in table-level encryption with KMS-backed keys. For regulated data at rest, use this combined with your on-premises KMS.
Cross-engine schema enforcement: When multiple engines write to the same Iceberg table, they all go through the same catalog. The catalog enforces schema evolution rules, preventing any single engine from accidentally dropping a column that another engine depends on.
Start with one regulated dataset, deploy an on-premises Polaris instance, and validate that your compliance team can trace every access back through the catalog audit log. Once that proof of concept holds up, expand to additional tables.
Building the Audit Trail for Regulators
Regulated institutions need to produce complete access records for auditors on demand. "Complete" means: who accessed which data, from which system, at what time, and what SQL they ran.
An Iceberg deployment built on Apache Polaris and Dremio gives you this at two levels. The Polaris catalog log captures every metadata request : table schema lookups, file location requests, and access control checks. The Dremio audit log captures every SQL query, the user who ran it, the tables accessed, and the result row count.
Combined, these logs provide a chain of custody from the user request through catalog authorization to storage access. That's the audit trail BAFIN auditors and FSA examiners expect.
Store both log streams in your compliance-approved log management system, not just in the vendor's infrastructure. If your regulation requires a 7-year retention window, configure your log export before you go to production.
Handling Engine Upgrades Without Data Migration
One benefit of the Iceberg format that's easy to overlook: you can upgrade your query engine without migrating your data.
With a proprietary warehouse, switching vendors means exporting every table, converting formats, and reloading. With Iceberg, your data stays in the same Parquet files on the same object storage. Upgrading from an older Trino version to a newer one, or switching from Spark to Dremio for interactive queries, requires only a catalog connection change : not a data migration.
For regulated institutions that move slowly on infrastructure changes (and most do), this matters. You can evaluate a new query engine against your production data before committing to a cutover. If the new engine produces different results on the same SQL, you investigate the discrepancy before you rely on the new system.
Dremio's Open Catalog architecture gives you a production-grade foundation for this model. Try Dremio Cloud free for 30 days to explore how the federated catalog model works.