Comparing the Top 2026 Agentic Analytics Tools: ThoughtSpot, Databricks, and Tableau

Comparing the Top 2026 Agentic Analytics Tools: ThoughtSpot, Databricks, and Tableau
The agentic analytics vendor landscape shifted significantly in 2025–2026. Every major BI and data platform added some form of natural language querying or AI agent capability. The terminology converged on "agentic analytics" while the architectures diverged considerably.
Choosing between these platforms requires clarity on what "agentic" actually means in each product's implementation : and which implementation matches your data architecture, your team's expertise, and your specific use cases.
Evaluation Criteria
Before comparing specific products, establish the criteria that matter. Agentic analytics platforms differ significantly on:
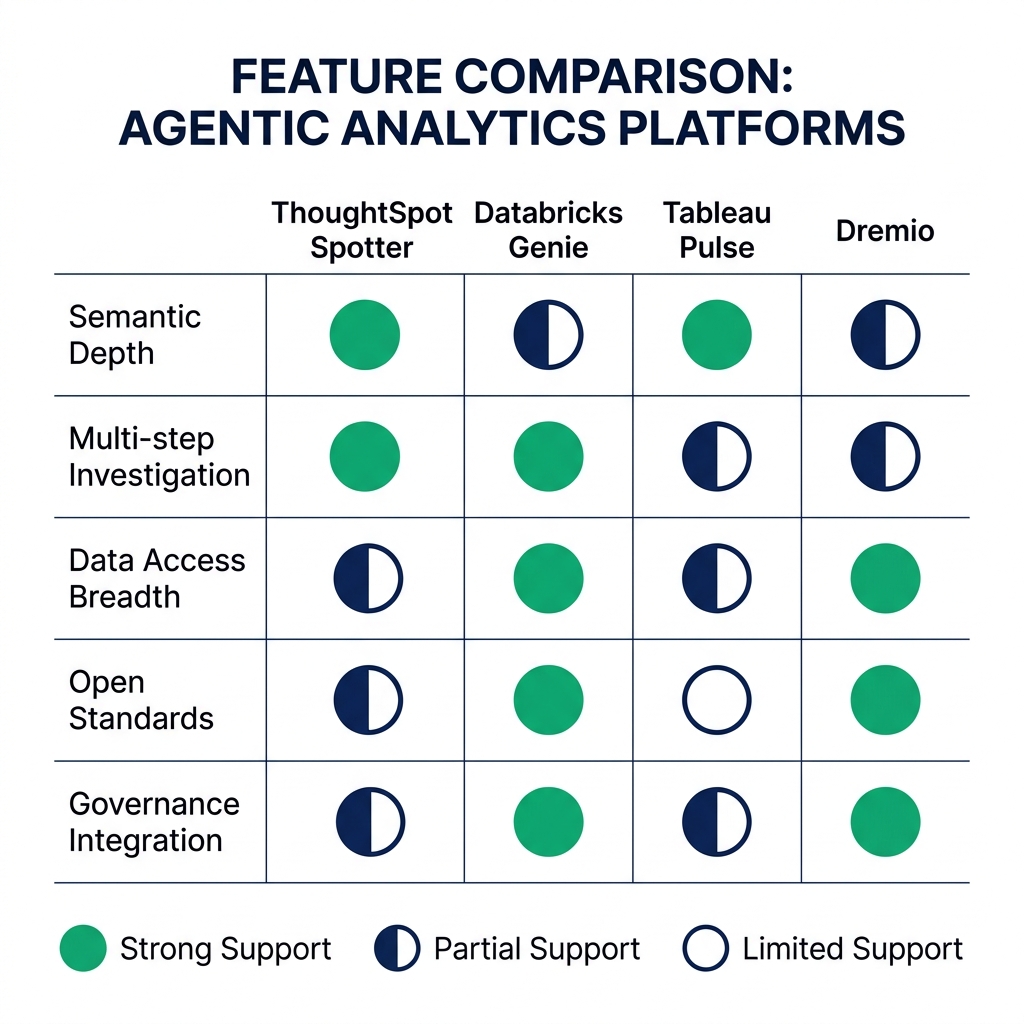
Semantic depth: How deeply does the platform understand the business meaning of data? Can it distinguish "revenue" from "gross revenue" from "net revenue" consistently? Does it respect your existing metric definitions, or does it generate its own interpretations?
Autonomy range: How complex are the analytical tasks the agent can perform autonomously? Single-query translation? Multi-step investigation? Anomaly detection and root cause analysis? Proactive monitoring?
Data access breadth: Can the agent reach all your data sources, or only data already ingested into the vendor's platform? Does it support federated queries across cloud environments?
Governance integration: Does the agent respect your access control policies? Does it enforce column masking for PII? Does it log its queries to your audit trail?
Open standards compatibility: Is the agent locked to the vendor's proprietary format, or does it work with open standards like Apache Iceberg and the Iceberg REST catalog?
ThoughtSpot
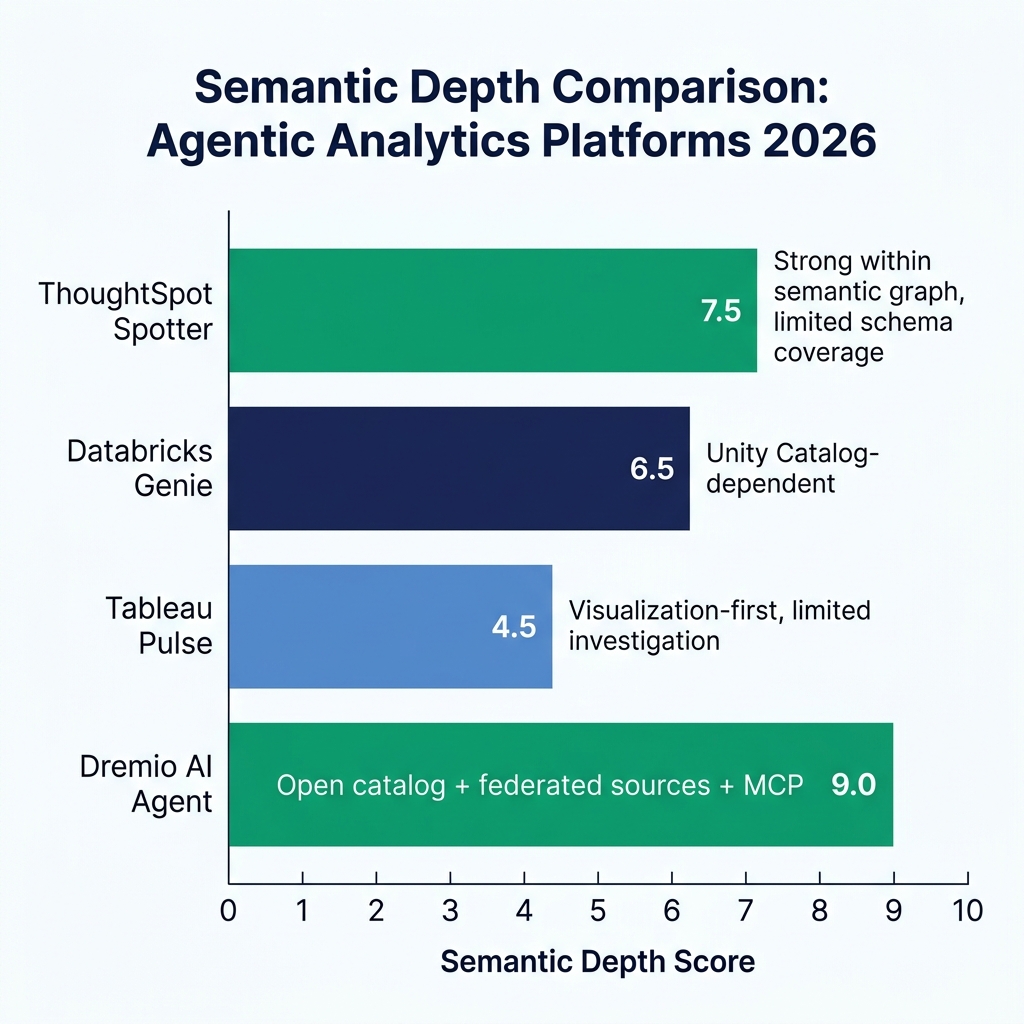
ThoughtSpot's agentic analytics story centers on Spotter, its AI agent built on top of the ThoughtSpot semantic graph. The semantic graph stores pre-defined relationships between tables, columns, and business metrics : essentially a structured representation of your business logic.
Spotter uses the semantic graph as grounding for its queries. When you ask about "revenue by region," Spotter resolves "revenue" to the canonical metric definition in the semantic graph before writing any SQL. This grounding makes Spotter relatively reliable for questions within the scope of the defined metrics.
The limitation is coverage. The semantic graph must be built and maintained manually. Metrics and relationships that aren't in the graph are outside Spotter's reliable scope. For organizations with well-maintained ThoughtSpot environments, this works well. For organizations with rapidly evolving schemas or metrics that haven't been formalized, the agent's coverage gaps are a practical constraint.
ThoughtSpot's data access model typically requires data to be ingested into ThoughtSpot's managed environment or connected through ThoughtSpot's supported connectors. Federated queries across arbitrary external sources are limited compared to dedicated federation platforms.
Databricks Genie
Databricks' AI/BI feature set, anchored by Genie, takes a different approach. Genie operates on data stored in the Databricks Lakehouse, which uses Delta Lake (Databricks' proprietary table format) or Unity Catalog-managed Iceberg tables.
Genie's strength is integration with the Databricks ecosystem: it can write SQL, Python, and more complex analytical workflows within a single platform. For teams already running Databricks for ETL, ML, and analytics, Genie provides a consistent interface across all of those workloads.
The semantic grounding in Genie relies on Unity Catalog's metadata and any additional context provided through Genie spaces : documented spaces where administrators define what data is available and provide natural language descriptions. The quality of Genie's responses is highly sensitive to how well those spaces are documented.
Data access is strongest within the Databricks environment. Federated queries to external sources work through Unity Catalog's external connection feature, but the federation depth is more limited than dedicated federation platforms.
Evaluation question to ask: What percentage of your data already lives in Databricks or Delta Lake? If it's over 80%, Genie is a reasonable choice. If you have significant data outside the Databricks ecosystem, the federation gap matters.
Tableau Pulse and Tableau AI
Tableau's agentic analytics offering evolved through 2024–2026 into Tableau Pulse and embedded Salesforce AI features. Pulse provides automated metric monitoring with natural language summaries : it's closer to automated reporting than autonomous investigation.
Tableau's AI features are strongest in the visualization and narrative generation layer. The agent produces charts, summarizes trends, and suggests related metrics to explore. It's less capable at multi-step analytical investigation compared to ThoughtSpot Spotter or Databricks Genie.
Tableau connects to a wide variety of data sources, but its query translation is engine-specific : it generates queries optimized for the connected data source rather than routing through a single SQL interface. For multi-source queries, you need to pre-join data before it reaches Tableau.
Best fit: Teams that want AI-enhanced dashboards and metric monitoring rather than autonomous multi-step investigation.
Where Dremio Fits
Dremio occupies a different position in this landscape. Rather than layering AI on top of a BI tool or a data platform that owns your data, Dremio's AI agent sits on top of a federated query engine that reaches your data wherever it lives.
The architecture difference matters for two reasons:
Data access breadth: Dremio's built-in AI agent can query across Iceberg tables, PostgreSQL databases, Snowflake, MongoDB, S3, and dozens of other sources through a single SQL interface. Other tools' agents are limited to data within or closely connected to their own ecosystem.
Semantic layer ownership: Dremio's semantic layer : virtual datasets, wikis, labels, lives in the catalog, not in the AI product. When you switch models or agents, the semantic context stays in Dremio and applies to any new agent you connect. No other tool's semantic configuration is portable in the same way.
Open standards: Dremio's MCP server allows external AI clients (Claude Desktop, ChatGPT, custom Python agents) to connect to Dremio's environment and use the same semantic context and governance model. You're not locked into Dremio's specific agent implementation.
Evaluation Questions for Your Organization
Use these questions to match your requirements to the right platform:
- Where does most of your data live? In one platform, or distributed across multiple systems?
- How well-defined are your canonical metrics? Do you have a semantic layer already?
- What analytical tasks do you need the agent to perform autonomously : single queries, multi-step investigations, or proactive monitoring?
- Do your agents need to respect existing access control policies (row-level security, column masking)?
- How important is it to connect external AI tools (ChatGPT, custom agents) to the same data and context?
If your answers point to distributed data, incomplete semantic definitions, and a need for governance integration, an open platform like Dremio that federates across sources and provides an open semantic layer is more flexible than a tool that requires your data to be centralized in its ecosystem.
Getting the Most from Any Agentic Analytics Platform
Regardless of which platform you choose, agentic analytics works better when you invest in the underlying data quality and documentation. Here's what matters:
Complete the semantic layer before deploying the agent. Every platform performs better when its semantic foundation is solid. Define your canonical metrics before asking the agent to generate them. Document your join paths before expecting correct multi-table queries. An agent deployed on undocumented data produces unreliable results, regardless of the underlying model quality.
Set clear scope boundaries. Agents that can access everything tend to go off-script. For production deployments, limit the agent's table access to the datasets relevant to its use case. A financial reporting agent doesn't need access to HR data. Scope limitation improves accuracy and reduces governance risk.
Build a testing harness. For any agentic analytics deployment, maintain a set of test questions with known correct answers. Run the agent against these questions weekly. Track accuracy over time. When a platform update changes the underlying model or schema changes affect the semantic layer, your test harness will catch regressions before users do.
Plan for misuse. Users will eventually try to ask the agent questions it can't answer reliably : questions outside the defined data scope, questions requiring business context that isn't in the catalog, or questions where the data simply doesn't exist. Design the agent's failure response to be useful: "I don't have visibility into Q3 2022 data because it's outside the retention window" is more useful than an incorrect answer that looks plausible.
Try Dremio Cloud free for 30 days and compare the agent's output quality against your current tool on the same analytical questions.