Trustworthy AI in the Agentic Lakehouse: Reconciling Concurrency and Isolation Contracts

Trustworthy AI in the Agentic Lakehouse: Reconciling Concurrency and Isolation Contracts
A single AI agent querying your lakehouse is manageable. A hundred AI agents : running automated monitoring, answering stakeholder questions, generating reports, and powering agentic workflows, create concurrency and isolation problems that traditional data architectures weren't designed for.
Human analysts are slow. They ask questions sequentially, pause to think, and rarely trigger more than a handful of concurrent queries against the same table. AI agents are fast and relentless. They can run dozens of queries per minute, issue transactions that interleave with other agents' writes, and hit edge cases in concurrency control that human query patterns never surface.
This post covers how Iceberg's optimistic concurrency control handles multi-agent write conflicts, how fine-grained access control prevents agents from accessing data outside their authorization scope, and what guardrail policies need to look like when autonomous systems have SQL access to production data.
Iceberg's Optimistic Concurrency Control for Multi-Agent Writes
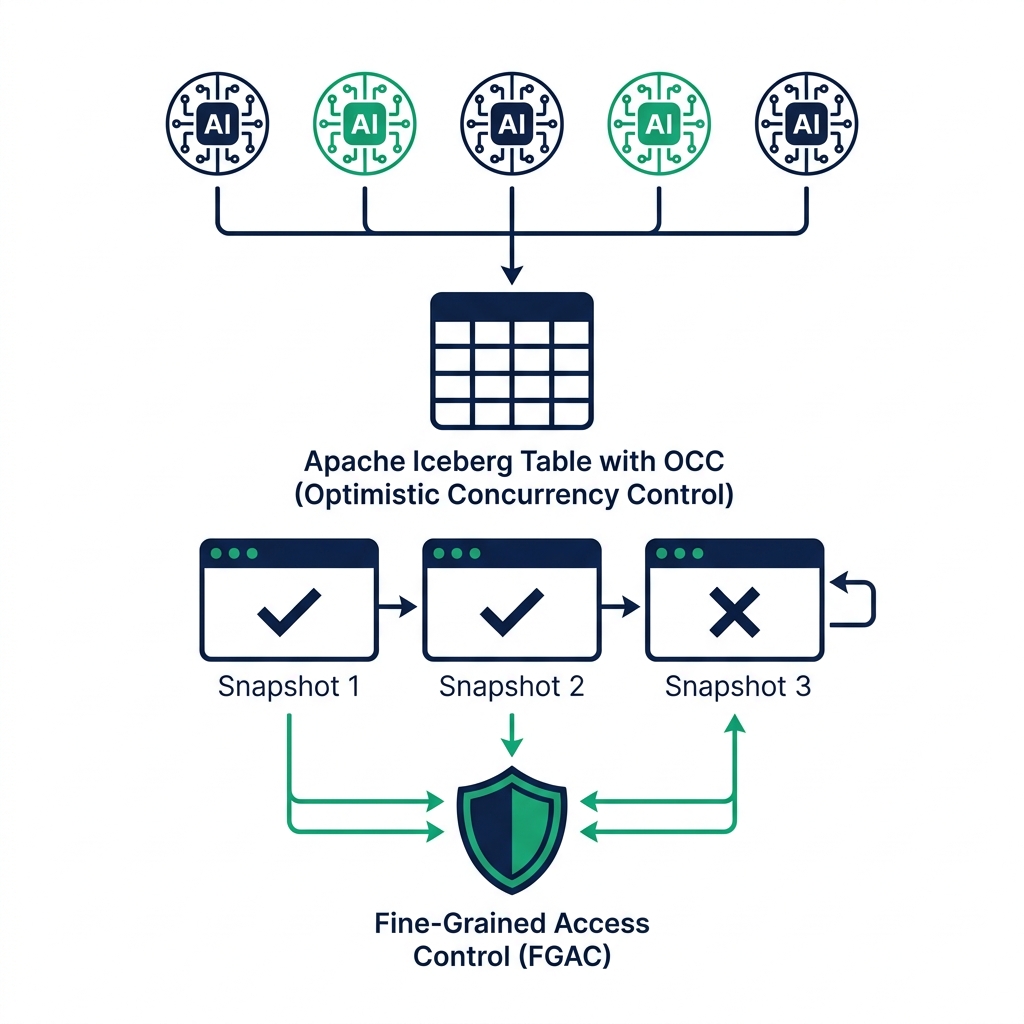
Apache Iceberg uses optimistic concurrency control (OCC) rather than pessimistic locking. In a pessimistic model, a writer acquires an exclusive lock before starting a write. In an optimistic model, the writer proceeds without a lock and validates at commit time that no conflicting write has occurred since it started.
The mechanics: every Iceberg table has a current snapshot ID. When an agent begins a write operation, it reads the current snapshot ID. When it's ready to commit, it attempts to update the table metadata to point to a new snapshot : but only if the current snapshot ID still matches what it read at the start. If another agent committed a conflicting change in the interim, the commit fails with a conflict error.
The key insight: not all concurrent writes conflict. Iceberg's conflict detection is partition-aware. Two agents writing to different partitions of the same table can both succeed without conflict. Two agents writing to the same partition conflict if their changes can't be merged safely.
For agentic analytics workloads where agents primarily read and occasionally write derived results (not raw source data), OCC provides practical concurrency with minimal blocking. The conflict rate is low when agents write to well-partitioned tables.
For agentic data pipeline scenarios where multiple agents might update the same partition simultaneously, the conflict rate increases. Design partitioning to minimize overlap between agents' write scopes.
Conflict Resolution Strategies
When OCC conflicts occur in a multi-agent system, the retry behavior matters.
Exponential backoff with jitter: The failed agent waits a random interval before retrying, with the interval growing on each retry. Jitter prevents synchronized retry storms where all conflicting agents retry at exactly the same time.
Idempotent writes: Design agent write operations so that re-running them after a conflict produces the same result. If an agent computes a metric and writes it to a results table, a retry after a conflict should produce the same metric value, not a duplicate row.
Write-through coordination: For scenarios with high write conflict rates, use a coordinator pattern: all agents that need to write to the same table submit writes to a coordinator agent, which serializes them and commits in order. This reduces concurrency but eliminates conflicts.
The choice depends on your conflict rate. Measure actual conflict rates in production. If conflicts are rare (under 1%), simple exponential backoff is sufficient. If conflicts are frequent, the write pattern needs redesign.
Fine-Grained Access Control for AI Agents
AI agents should have the minimum access necessary to perform their function. An agent that generates revenue reports doesn't need access to employee compensation tables. An agent monitoring operational pipelines doesn't need to read customer PII.
Dremio's fine-grained access control (FGAC) enforces these restrictions consistently across all agent connections. An agent's service principal is bound to a role, and that role defines exactly which tables the agent can read, which columns are visible, and which rows fall within its authorized scope.
Column masking for AI agents: When an agent with an analyst role queries a table containing SSNs, the SSN column returns masked values (****-**-1234). The agent can't request unmasked data even if it generates SQL that directly references the SSN column : the masking is enforced by the query engine before results are returned.
Row-level filtering: An agent responsible for North America operations sees only North American rows, even if it generates a query without a regional filter. The filter is applied automatically based on the agent's role context.
Time-limited access tokens: Agent credentials should expire frequently : hourly or more often for high-privilege agents. Long-lived tokens that are compromised or leaked provide extended unauthorized access. Dremio's token-based authentication supports short-lived credentials appropriate for agent workloads.
Guardrail Policies for Autonomous SQL Access
Governance policies for AI agents need to anticipate behaviors that don't occur with human analysts:
Query cost limits: AI agents can generate unexpectedly expensive queries : full table scans without filters, recursive CTEs with large intermediate result sets, or aggregations across billions of rows that a human analyst wouldn't attempt interactively. Implement query cost estimation limits that reject or queue queries above a compute budget threshold.
Write operation restrictions: Most AI agents should be read-only. An agent that can write to production tables can modify data, drop snapshots, or corrupt table state if it generates incorrect write SQL. Use read-only service principals for analytics agents. Restrict write access to pipeline agents with tightly defined write patterns.
Rate limiting per agent: An AI agent responding to a wave of stakeholder questions might generate hundreds of queries in a short period. Rate limiting prevents a single agent workload from consuming all available query capacity.
Audit log requirements: Every query an AI agent executes should be logged with the agent's identity, the query text, the tables accessed, and the execution result. This is the foundation for compliance audits and for diagnosing incorrect agent behavior after the fact.
Scope constraints in the system prompt: For agent implementations that use LLM-based reasoning, the system prompt should explicitly tell the agent which tables it's authorized to use. Even if access control prevents unauthorized access at the engine level, a clear scope in the prompt prevents the agent from generating queries that will fail, wasting compute and slowing response time.
Isolation Contracts: What Each Agent Can See
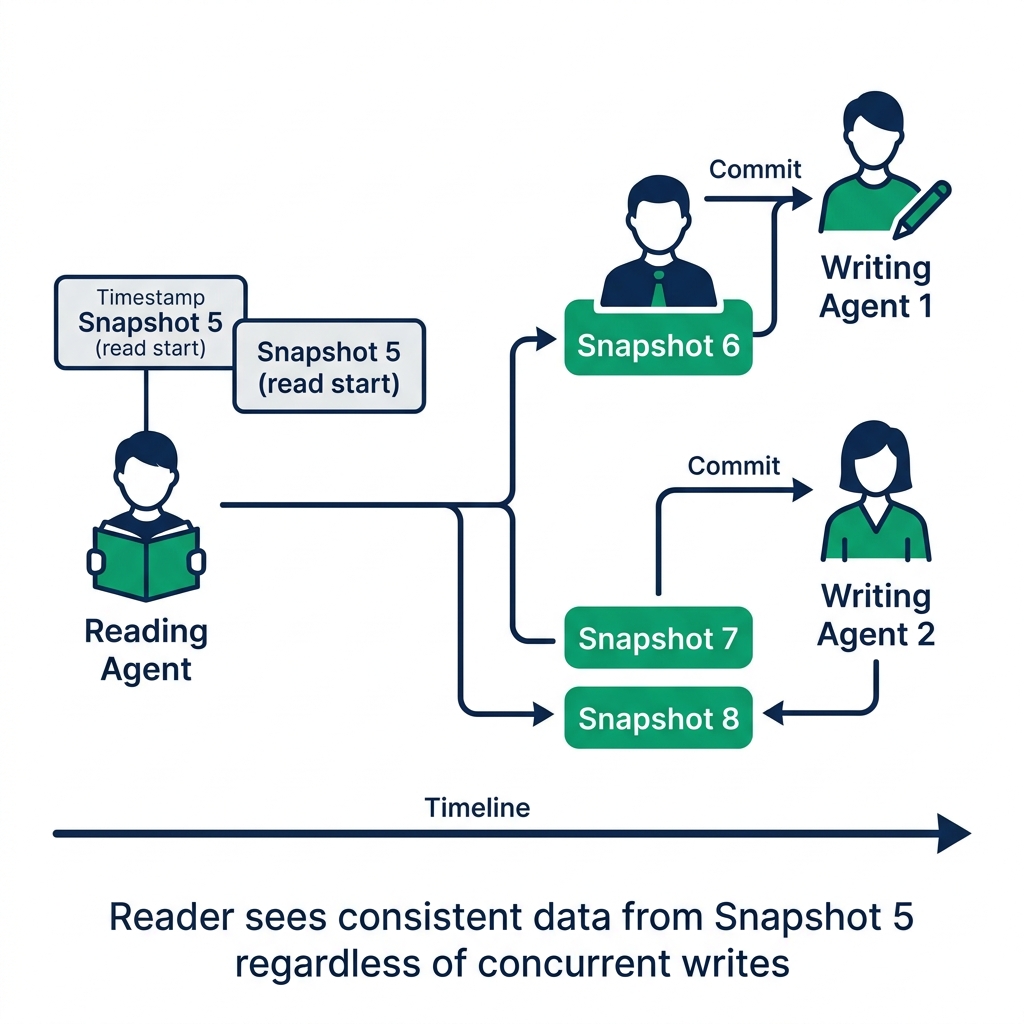
When hundreds of agents run concurrently, isolation means each agent sees a consistent view of the data, unaffected by other agents' concurrent writes.
Iceberg's snapshot-based reads provide this automatically. When an agent starts a read, it reads from the current snapshot. Concurrent writes by other agents create new snapshots. The reading agent continues reading from its starting snapshot until its query completes : it never sees partial data from an in-progress write.
This is the same isolation guarantee that makes Iceberg safe for concurrent human users. It extends naturally to AI agents, regardless of concurrency level.
The edge case: an agent that starts a long-running investigation (10 minutes) and then writes a derived result to a results table may be writing based on data that's 10 minutes old. Other agents that have written in the interim have created newer snapshots. The result the long-running agent writes is consistent with its starting state but may not reflect the latest committed data.
For most analytical workloads, this is acceptable : a 10-minute-old result is still a valid analytical result. For operational dashboards requiring the latest data, keep investigation tasks short enough that the staleness is within tolerance.
Testing Concurrency at Scale
Before deploying a multi-agent agentic system to production, load test at the expected concurrency level.
Generate synthetic agent workloads: N agents, each running a realistic mix of investigation queries, metadata lookups, and occasional writes. Run for 30 minutes and measure:
- OCC conflict rate (should be under 5% for well-designed write patterns)
- Query latency percentiles under concurrent load (P50, P95, P99)
- Cache hit rates (Dremio's C3 cache should show high hit rates for repeated agent query patterns)
- Error rates for rate-limit violations and access control rejections
Any failure modes discovered during load testing are better discovered in staging than in production. Tune rate limits, retry policies, and write patterns based on the results.
Try Dremio Cloud free for 30 days and run your multi-agent concurrency tests against a production-grade agentic lakehouse.