The 2026 Unified Data Architecture: Reconciling Multi-Cloud Data Lakehouses

The 2026 Unified Data Architecture: Reconciling Multi-Cloud Data Lakehouses
Three years ago, "multi-cloud strategy" for data meant maintaining separate warehouses on AWS, Azure, and GCP, then running ETL to sync them. Teams spent more time on pipeline maintenance than on actual analysis. That approach is giving way to something simpler: a shared table format, a unified catalog, and a query engine that reaches across cloud boundaries without moving data.
The 2026 unified data architecture isn't a single product. It's a stack of composable layers held together by open standards. This post explains what those layers are, how they fit together, and where the real complexity lives.
Why Multi-Cloud Data Is Still Hard
Multi-cloud data deployments exist for several reasons: different cloud regions for data residency compliance, different providers for different workloads (AWS for ML, Azure for enterprise apps), acquisitions that bring in existing infrastructure, or deliberate vendor diversification.
The problem is that each cloud's native analytical services are optimized for data stored in that cloud's own object storage, in that cloud's preferred format. BigQuery is fast on BigQuery storage. Redshift is fast on Redshift clusters. Neither was designed to read data stored in the other's format, and both charge egress fees when data moves between clouds.
The result: organizations running on multiple clouds end up with data silos tied to each cloud, even if the data is conceptually the same dataset.
Apache Iceberg changes the equation because it stores data in open Parquet files on any S3-compatible object storage. Multiple engines can read the same Iceberg table without copying it. The catalog tracks where the files are. The compute engine comes to the data.
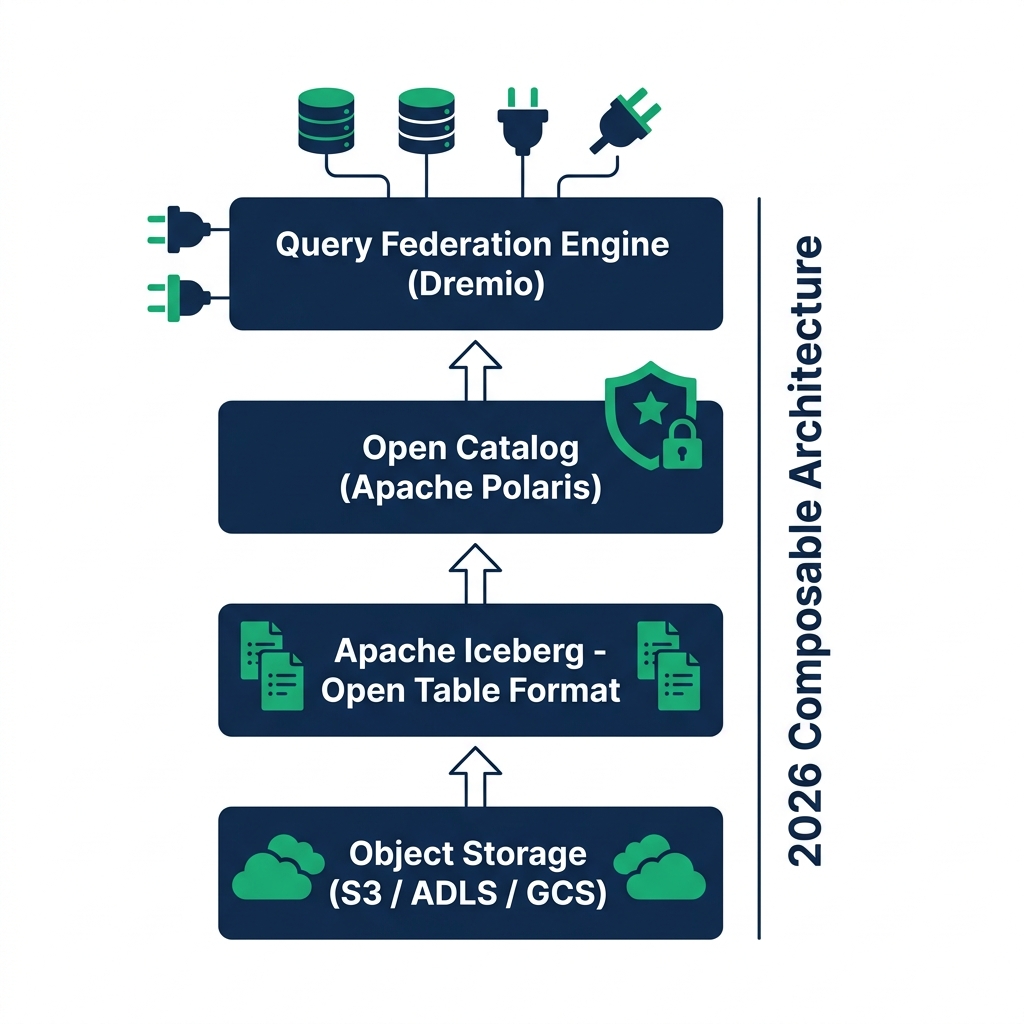
The Four Layers of the 2026 Composable Architecture
Layer 1: Open Storage
Data lives in object storage : S3, Azure Data Lake Storage, GCS, in Parquet files organized by the Iceberg spec. The storage tier is the cheapest and the most portable. Moving from one object store to another is an infrastructure-level operation, not an application-level one.
Layer 2: Open Table Format
Apache Iceberg provides the metadata layer: manifest files, snapshot history, partition structure, schema evolution. Any engine that reads Iceberg can read these tables. The format is standardized, open-source, and governed by the Apache Software Foundation.
Layer 3: Open Catalog
The catalog tracks which Iceberg tables exist, where their metadata files live, and what access control policies apply. Apache Polaris is the open-source reference implementation of the Iceberg REST catalog spec. Dremio's Open Catalog extends Polaris with federated source connections, bringing non-Iceberg data sources (databases, cloud warehouses, object storage) into the same governed namespace.
Layer 4: Query Federation
The query engine reads from the catalog, finds file locations, reads Parquet data from object storage, and returns results. Dremio's query federation connects to multiple catalogs and data sources : from different cloud environments, and executes cross-source SQL queries without moving data. Predicate pushdown reduces how much data crosses the network.
Zero-ETL Federation: What It Means in Practice
Zero-ETL federation means querying data where it lives instead of ingesting it first. Dremio connects directly to a Snowflake schema, an operational PostgreSQL database, an AWS Glue catalog, and an on-premises Iceberg table, then executes a single SQL query that joins data from all four sources.
The analyst writes one query. Dremio breaks it into source-specific subqueries, pushes predicates to each source, retrieves only the filtered results, and assembles the final answer. No ETL pipeline. No data duplication. No stale data from a batch sync that ran last night.
The tradeoff: federated queries that span many sources depend on network latency between the query engine and each source. For high-frequency dashboards, Dremio's Reflections feature creates pre-computed materializations of frequently-queried federated data. The materialization runs at the scheduled refresh interval; the dashboard query reads from the local materialized copy.
Multi-Cloud Routing for Cost Efficiency
When you separate compute from storage using Iceberg, you can route different workloads to different compute environments without migrating the data.
Batch ELT runs on spot Spark clusters in the cloud region where the data is stored : no egress. Interactive queries for a business unit in Europe run through a Dremio cluster in an EU region, accessing an EU Iceberg table directly. Global reporting that needs to join EU and US datasets runs through a central Dremio instance with federated connections to both regions.
Each layer is independently scalable. You don't pay for idle compute in regions where no active queries are running. You don't pay for data movement when you can push the query to the data instead.
Governance Across Clouds
The governance challenge in multi-cloud lakehouses is maintaining consistent access policies across environments that each have their own IAM systems.
Dremio's Open Catalog acts as a unified governance layer on top of those environment-specific IAM policies. It enforces role-based access control, fine-grained row and column policies, and audit logging through a single interface, regardless of whether the underlying data lives in AWS, Azure, or on-premises.
When a compliance team needs to demonstrate that European customer data was never accessed by US-based compute, the Dremio audit log captures every query with the user identity, source table, and execution environment. That's the audit trail that regulated organizations need.
Dremio's AI semantic layer extends this governance model to AI agents: virtual datasets with access control ensure that AI queries against sensitive data go through the same masking and filtering rules as human queries. An AI agent can't access more data than a human analyst with the same role.
AI Agents in the Unified Architecture
The unified data architecture is also the prerequisite for reliable agentic analytics. An AI agent that needs to answer business questions across multi-cloud data sources needs three things: a single SQL interface that reaches all sources, a semantic layer that documents what the data means, and access control that limits the agent's scope to its authorized data.
All three are properties of the unified architecture described above. The federated query engine provides the single SQL interface. The Open Catalog's wiki and virtual dataset documentation provides the semantic layer. The RBAC policies enforced by the catalog define the agent's access scope.
Without this architecture, AI agents working on multi-cloud data face the same fragmentation problem that human analysts do : needing to switch contexts between tools, manually joining data from separate sources, or relying on ETL pipelines that are always slightly out of date.
Dremio's MCP server exposes the unified catalog to external AI clients, including Claude, ChatGPT, and custom LangChain agents. The agent connects once, sees all authorized sources through a single namespace, and queries across cloud boundaries using standard SQL. The architecture that makes multi-cloud data manageable for human analysts makes it reliable for AI agents.
Common Failure Modes in Multi-Cloud Lakehouse Projects
Multi-cloud lakehouse projects fail in predictable ways. Understanding them upfront helps you avoid the common traps:
Over-federating without Reflections: Federation handles flexible, one-off queries well. For high-frequency dashboard queries that join several large tables, pure federation is too slow. Teams that don't plan for materialization end up with dashboards that time out or force a return to ETL. Build your Reflections strategy before you roll out dashboards.
Ignoring egress costs during design: Federated queries avoid data movement in normal operation, but some patterns still trigger egress : cross-region joins where both datasets are large, queries that can't push predicates effectively, or Reflections that refresh across cloud boundaries. Map your query patterns to egress scenarios before choosing your compute placement strategy.
Skipping the semantic layer: The unified architecture solves the data access problem but doesn't solve the data understanding problem. If your catalog is not documented : no wikis, no column labels, no canonical virtual datasets, your users (human and AI) will query the wrong tables, use inconsistent metric definitions, and lose confidence in results. Build the semantic layer in parallel with the connectivity layer, not after.
Treating the catalog as optional: Teams that deploy Dremio for query federation but skip the Open Catalog setup lose the governance and semantic benefits. The catalog is what converts a query engine into a governed data platform. It's not optional infrastructure for production deployments.
Start with One Region, Expand Deliberately
The unified multi-cloud architecture works best when you build it incrementally. Start by centralizing access to your existing data through Dremio without moving anything. Connect your data sources as federated connections. Identify the high-value queries that currently require ETL, and test whether Reflections-based materialization gives you acceptable performance.
Once the pattern holds for one region and a handful of sources, extend it to additional regions and additional sources. The open catalog standard means new sources connect through the same interface regardless of where they live.
Try Dremio Cloud free for 30 days and start federating your multi-cloud data sources from day one.