Why Traditional Lakehouses Fail AI Agents: The Mathematical Case for the Agentic Lakehouse

Why Traditional Lakehouses Fail AI Agents: The Mathematical Case for the Agentic Lakehouse
When organizations first try connecting an LLM to their data lakehouse, the experience follows a predictable pattern: early demos work surprisingly well, production queries fail in embarrassing ways, and teams spend months debugging why the AI produces confident, plausible, wrong answers.
The failure isn't the LLM. The failure is the data architecture.
A traditional lakehouse was designed for human analysts who bring implicit knowledge to every query session. Column named amt_q3_fy24_usd? A human analyst asks a colleague what that means. An AI agent does not : it guesses, and its guess is based on statistical patterns from its training data, not the actual business definition at your company.
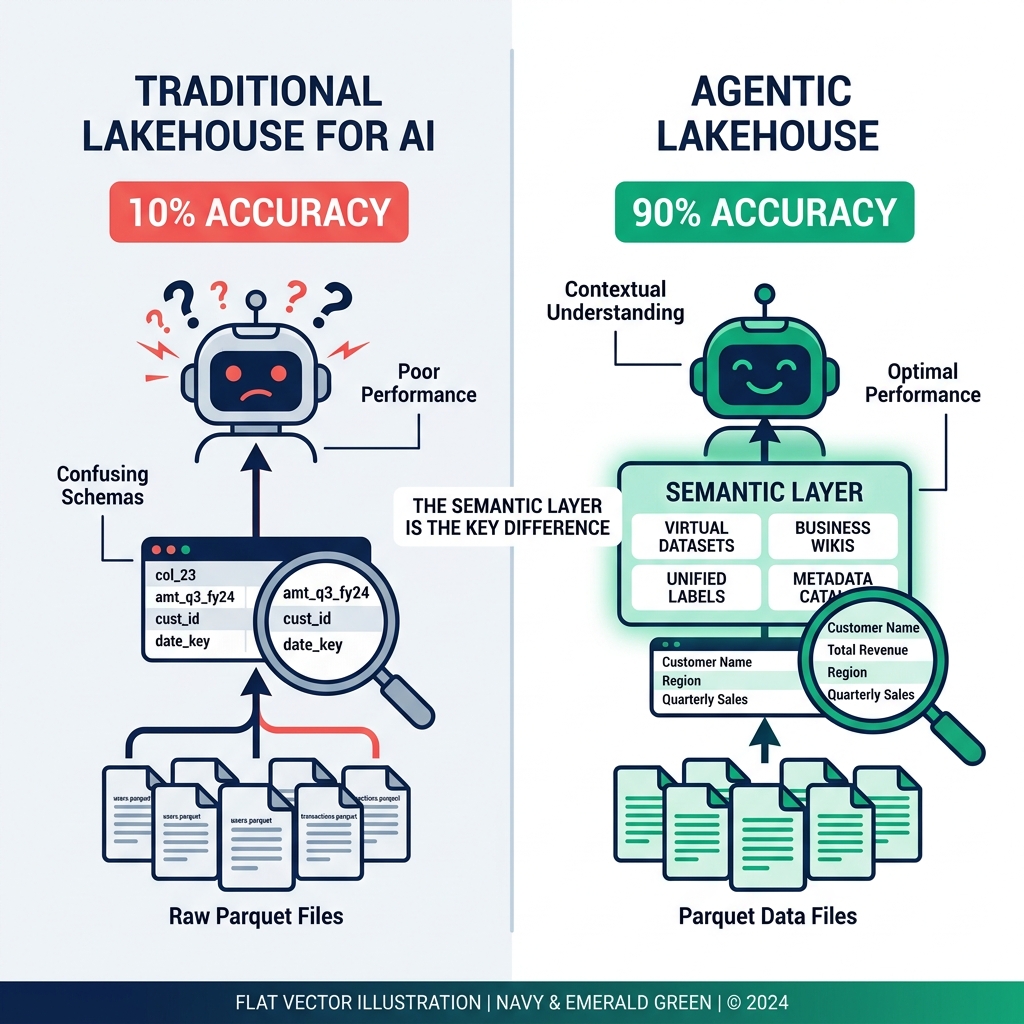
The Common-Sense Context Gap
Humans navigate ambiguous schemas through implicit knowledge and social querying. "What does cust_flg mean?" gets answered in 30 seconds by asking the data owner. AI agents can't ask questions unless they have a tool specifically designed for that purpose, and most traditional lakehouse setups don't provide one.
The LLM fills the gap with statistical inference. It's seen thousands of database schemas in its training data. cust_flg probably means customer flag. Which flag? The model's best guess based on other columns in the context. That guess is right sometimes and wrong in ways that are impossible to detect without knowing the ground truth.
The problem compounds with scale. A traditional lakehouse with 500 tables has hundreds of ambiguous column names, inconsistent naming conventions across teams, multiple definitions of the same business concept in different tables, and no machine-readable documentation of which tables are authoritative vs. deprecated.
When an AI agent explores this environment, its probability of generating correct SQL decreases with each additional ambiguity it encounters. A query that requires joining three tables, each with naming inconsistencies and undocumented column semantics, has a much lower probability of being correct than a query against a single, well-documented table.
The Semantic Barrier: A Probabilistic View
Let's formalize this with a simple model. Assume each column in your schema has a probability P(correct) of being interpreted correctly by an AI agent without additional context. For a well-named, self-explanatory column like order_date, P(correct) might be 0.98. For a poorly named column like flag_3, P(correct) might be 0.40.
A SQL query that involves N column references has a combined correctness probability of approximately:
P(query correct) ≈ P(col_1) × P(col_2) × ... × P(col_N)For a 10-column query with an average per-column probability of 0.80:
P(query correct) ≈ 0.80^10 ≈ 0.107That's roughly a 10% chance the full query is interpreted correctly. For complex analytical queries with 20+ column references across multiple tables, the probability approaches zero.
This is the mathematical case for why putting an AI agent directly on top of a traditional lakehouse produces unreliable results. The agent isn't making single mistakes : it's making compounding probabilistic errors across every ambiguous element it encounters.
The Semantic Barrier in Practice
Three specific failure modes appear repeatedly when AI agents encounter traditional lakehouses:
Metric inconsistency: Your marketing team defined "active user" as anyone who logged in this month. Your analytics team defined it as anyone who placed an order this month. The lakehouse has tables from both teams. The agent picks one definition arbitrarily and uses it consistently : consistently wrong for half of your stakeholders.
Stale table selection: The lakehouse has both orders_v1 and orders_v2 tables. v2 replaced v1 eight months ago. Without documentation indicating which is current, the agent sometimes uses v1 (which still has more historical data), producing counts that include duplicate records from the migration period.
Type coercion errors: A column defined as VARCHAR actually contains dates in YYYY-MM-DD format. The agent generates a date filter without explicit CAST, which works in some SQL dialects and silently returns all rows in others.
Each of these produces a confident, wrong answer. The agent doesn't know it's wrong : it didn't hallucinate from nowhere, it made a reasonable inference from the context available. The context was insufficient.
What an Agentic Lakehouse Provides
The agentic lakehouse solves the common-sense context gap by building business context into the data layer, not into the agent's prompt.
Virtual datasets as canonical definitions: Instead of exposing raw tables to the agent, an agentic lakehouse exposes SQL-defined views that encode business logic. "Active users" is a virtual dataset with the correct, agreed-upon definition. The agent queries the virtual dataset, and the underlying logic is correct by construction.
Wikis and labels as machine-readable documentation: Each table and column has structured documentation: what it contains, what business concept it maps to, whether it's the authoritative source or a derivative, what PII classification it carries. The agent queries this documentation when it needs context, rather than inferring from column names.
Medallion architecture for trust levels: Bronze tables are raw and untrusted. Silver tables are cleaned, typed, and business-ready. Gold tables are purpose-built aggregations. The agent knows which tier to use for which type of question. It doesn't have to guess which orders table is the authoritative one.
Fine-grained access control: The agent can only access what its role permits. PII columns are masked. Rows outside the agent's authorized scope are filtered. The same governance model that applies to human analysts applies to AI agents automatically.
Dremio's Agentic Lakehouse implements all four components. The semantic layer provides virtual datasets and documented metadata. The AI agent consults the semantic layer before generating queries. The query federation engine connects to all data sources through the same governed interface.
The Mathematical Improvement
Returning to the probabilistic model: a semantic layer with rich, accurate documentation changes the per-column correctness probabilities dramatically.
For columns exposed through well-documented virtual datasets, P(correct) approaches 0.99 : because the column name corresponds to a canonical business definition the agent can look up.
For a 10-column query where every column comes from documented virtual datasets:
P(query correct) ≈ 0.99^10 ≈ 0.904That's a move from ~10% to ~90% reliability for complex queries : achieved not by improving the LLM, but by improving the data layer it operates on.

The model is simplified : real correctness probabilities depend on many factors, but the directional effect is real. The investment in semantic layer documentation pays directly in AI agent accuracy.
Starting the Transition
The transition from a traditional lakehouse to an agentic lakehouse is incremental. You don't need to document every table before you start.
Begin with the 10–20 most frequently queried datasets. Create virtual datasets with canonical business logic. Write wiki documentation for every column in those datasets. Classify PII columns. Test the agent against those datasets and measure whether its accuracy improves.
Then expand to the next tier of datasets. Each documented dataset extends the reliable scope of the agent.
Try Dremio Cloud free for 30 days and start building the semantic layer that makes your AI agents reliable.