The Era of Zero-ETL Federation: Fueling AI Agents with Real-Time Cross-Enterprise Data

The Era of Zero-ETL Federation: Fueling AI Agents with Real-Time Cross-Enterprise Data
ETL pipelines were the right answer in 2010. You pulled data from operational systems nightly, transformed it, and loaded it into the warehouse. Analysts got yesterday's data by 8 AM. The tradeoff was acceptable.
The tradeoff is no longer acceptable for agentic analytics. An AI agent investigating a revenue anomaly needs today's Salesforce opportunity data, not last night's batch. An agent monitoring supply chain risk needs the current inventory system state, not a snapshot from six hours ago. Batch ETL introduces a latency floor that makes certain classes of analytical questions unanswerable in time to act on them.
Zero-ETL federation is the answer: the query engine reaches the data where it lives, when you need it, without a separate pipeline copying it first.
Why Batch ETL Limits Agentic Analytics
Traditional ETL follows a fixed cadence. Data lands in the analytical system hours or days after it was created in the operational system. That gap is the latency floor : the minimum time between an event happening and an agent being able to analyze it.
For retrospective analysis (what happened last quarter), batch ETL is fine. The latency floor doesn't matter when the questions are about history.
For agentic analytics focused on current business conditions, batch ETL creates real problems:
Stale anomaly detection: An AI agent monitoring revenue might detect an anomaly in yesterday's data that actually resolved itself six hours ago. The agent's investigation and alert are based on a state that no longer exists.
Incomplete cross-system joins: When a customer churn prediction agent needs to join support ticket data (from a real-time source) with purchase history (in the lakehouse), a batch ETL approach requires either waiting for the next batch or running two separate analyses that can't be easily joined.
Decision lag: Agents supporting operational decisions : sales prioritization, inventory allocation, customer routing, need current data to produce actionable recommendations. A 12-hour lag in the underlying data produces recommendations that are 12 hours behind reality.
The Federation Architecture
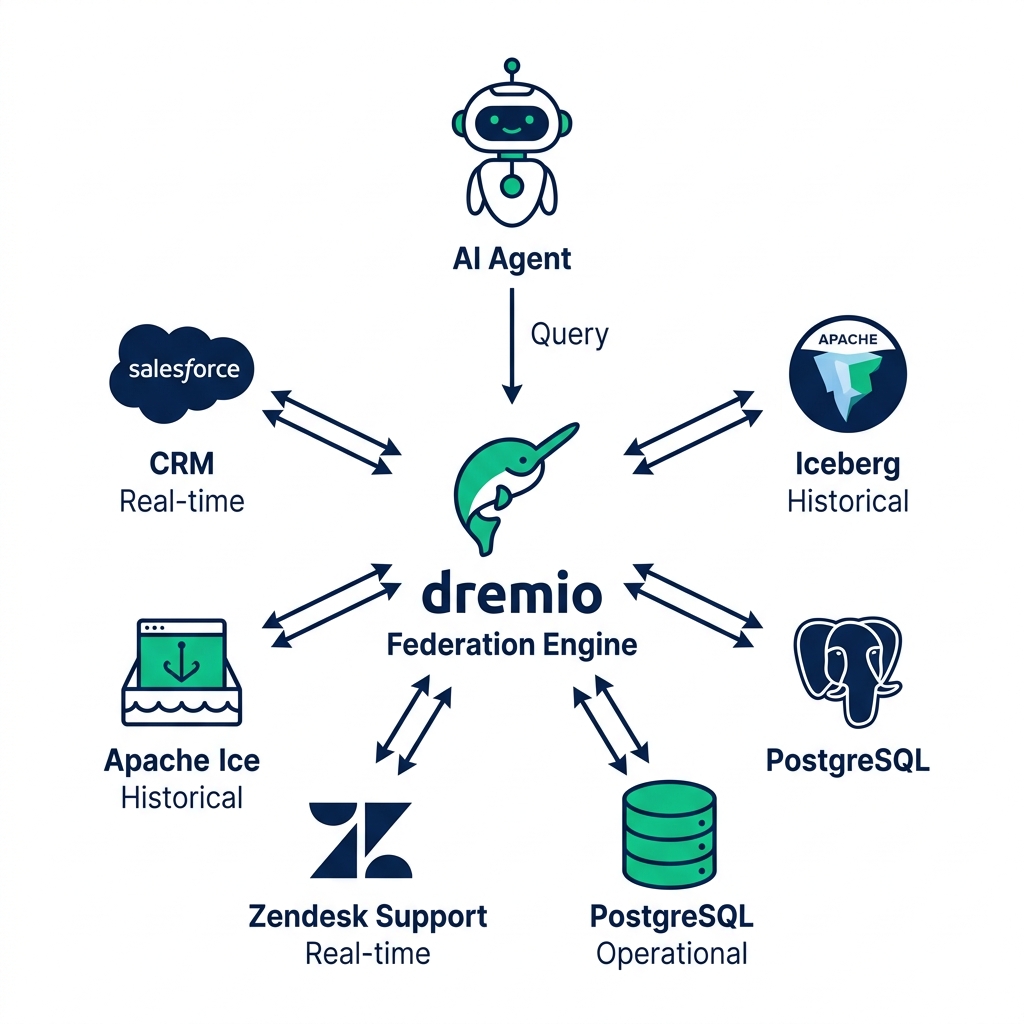
Zero-ETL federation routes queries directly to source systems at query time. The query engine acts as the router : it receives a SQL query from an AI agent, identifies which tables come from which sources, sends source-specific subqueries to each source, and assembles the results.
Dremio's federation architecture connects to sources through source-specific connectors:
- Relational databases: PostgreSQL, MySQL, Oracle, SQL Server : queried via JDBC with predicate pushdown
- Cloud warehouses: Snowflake, BigQuery, Redshift : queried through their native query APIs
- Object storage: S3, GCS, ADLS : Iceberg or raw Parquet, queried directly
- SaaS systems: Salesforce, Zendesk, HubSpot : queried through API-based connectors
- Streaming systems: Kafka, Kinesis : queried through streaming-to-SQL adapters
Each source appears in Dremio's unified namespace. An agent queries the namespace without needing to know which underlying system holds which data.
Predicate Pushdown: The Key to Federation Performance
Without optimization, federated queries are slow. A naive approach reads all rows from every source, transfers them to the query engine, and performs joins in memory. For large operational tables, this is impractical.
Predicate pushdown changes the pattern: the query engine analyzes the SQL, identifies filter conditions that can be applied at the source, and sends those filters as part of the source-specific subquery. The source returns only the rows that match the filter.
For a query that joins Salesforce opportunities with Iceberg revenue data, filtered to opportunities created in the last 7 days in the North America region:
Without pushdown:
- Fetch all Salesforce opportunities (millions of rows)
- Fetch all revenue data (terabytes)
- Apply filters in Dremio's memory
With pushdown:
- Send to Salesforce:
SELECT * FROM opportunities WHERE created_date > '2026-05-21' AND region = 'NA': returns thousands of rows - Send to Iceberg:
SELECT * FROM revenue WHERE date > '2026-05-21' AND region = 'NA': reads only matching partitions - Join the small result sets in Dremio's memory
Predicate pushdown can reduce the data volume transferred by 99%+ for well-filtered queries. The query runs in seconds instead of minutes.
Dremio pushes predicates to all source types it supports. The effectiveness depends on the source system's ability to process the predicate efficiently. Columnar sources like Parquet files and columnar databases handle pushdown very well. Row-oriented databases handle simple equality and range predicates well, but complex analytical predicates may be partially pushed.
Real-Time CRM and Lakehouse Joins: A Practical Pattern
The most common zero-ETL federation use case in agentic analytics is joining current CRM data with historical lakehouse data.
Scenario: An agent is investigating why churned customers in Q1 had lower lifetime value than churned customers in previous quarters.
The agent needs:
- Current account status and churn date from Salesforce (real-time)
- Historical purchase history from the Iceberg lakehouse (historical)
- Customer support ticket history from Zendesk (real-time)
With zero-ETL federation, the agent writes one query:
SELECT
s.account_id,
s.churn_date,
s.contract_value,
SUM(r.revenue_usd) AS lifetime_revenue,
COUNT(DISTINCT z.ticket_id) AS support_tickets_lifetime,
AVG(z.resolution_days) AS avg_resolution_days
FROM salesforce.accounts s
JOIN datalake.canonical_revenue r ON s.account_id = r.customer_id
JOIN zendesk.tickets z ON s.account_id = z.account_id
WHERE s.status = 'churned'
AND s.churn_date BETWEEN '2026-01-01' AND '2026-03-31'
GROUP BY 1, 2, 3
ORDER BY lifetime_revenue DESCDremio executes this against all three sources simultaneously, applying date and status filters at each source, and joins the results. The agent gets a complete cross-system analysis without any pipeline building.
The same query run yesterday in a batch ETL model would have required: a Salesforce extraction job, a Zendesk extraction job, waiting for both to land in the warehouse, and then running the analysis on potentially 24-hour-old data.
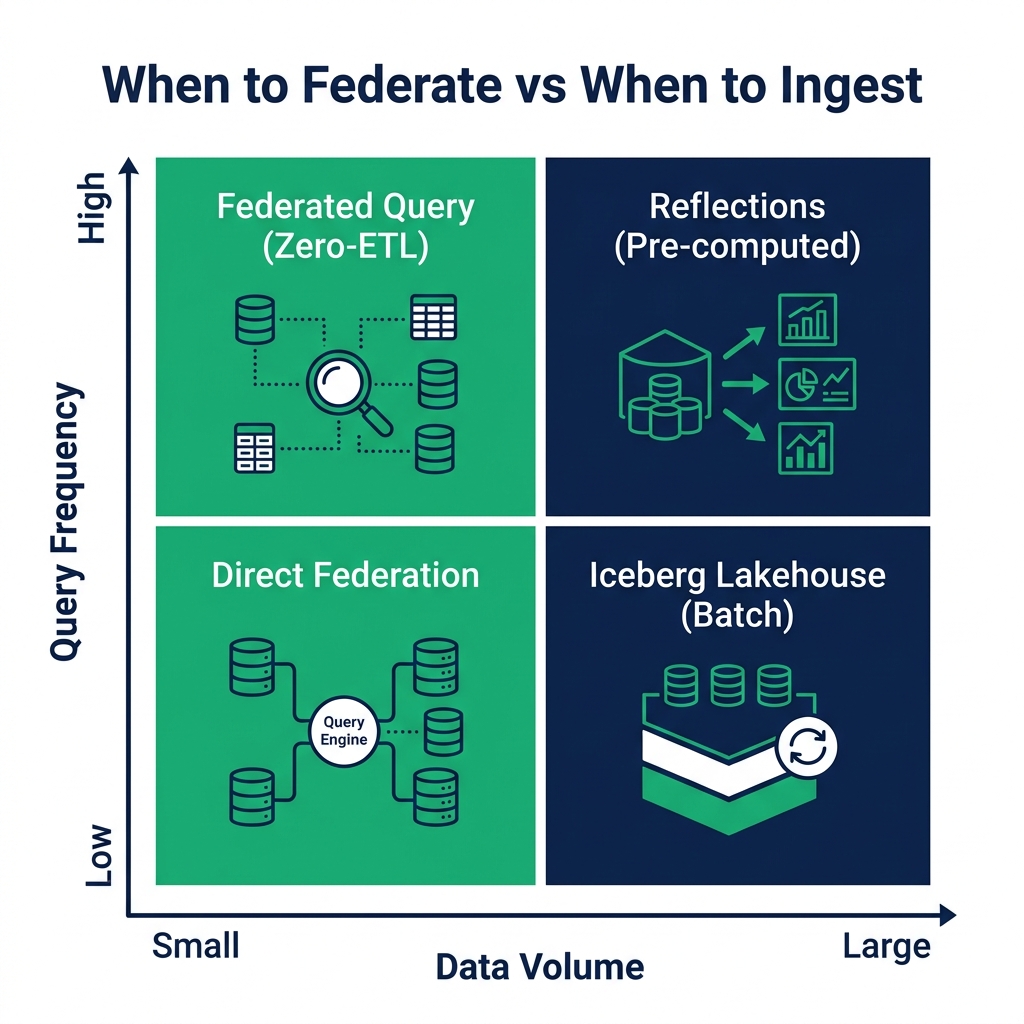
The Tradeoffs: When Federation Works and When It Doesn't
Zero-ETL federation is not the right answer for every data integration pattern.
Works well for:
- Current-state analysis where the operational system data is the freshest available
- Low-to-medium volume operational joins (millions of rows, not billions)
- Exploratory or investigative queries run by agentic systems
- Cases where pipeline maintenance cost exceeds the query execution overhead
Works less well for:
- High-frequency repetitive queries against slow source systems (federation overhead adds up)
- Very large volume joins where pushdown can't reduce data sufficiently
- Source systems with strict rate limits or connection limits that batch queries would exhaust
- Complex transformations that need to run at ingestion time, not at query time
Dremio's Reflections bridge some of the gap between federation and performance. When a federated query pattern runs frequently, create a Reflection that pre-computes it on a refresh schedule. The agent's interactive queries hit the Reflection; the source system isn't queried on every request.
Hybrid architectures are the norm: real-time federation for current operational state, pre-computed Reflections for high-frequency analytical patterns, and Iceberg tables for historical data that has been cleaned and enriched.
Federation as the AI Agent's Data Access Layer
For agentic analytics, federation is the mechanism that makes the AI agent a real-time analytical system rather than a historical one. The agent's ability to answer "what is happening right now" depends on federation reaching current operational systems. Its ability to answer "what happened in the past" depends on the historical lakehouse.
Dremio's query federation connects both layers through the same interface, with the same semantic layer providing business context for both real-time and historical data. The agent doesn't need to know which source has which data : the unified namespace handles that routing.
The era of zero-ETL federation means AI agents can answer business questions about current conditions and historical context in a single investigation, without waiting for a batch pipeline to complete.
Try Dremio Cloud free for 30 days and run your first zero-ETL federated query against your operational systems.