What Is LTAP in the Lakehouse?

What Is LTAP in the Lakehouse?
Lakehouse transactional analytical processing is useful only when teams define freshness, isolation, and workload boundaries clearly. For data architects evaluating mixed analytical and operational workloads, the useful question is what changes in production and what simply sounds current.
The Real LTAP Question Is Not Whether a Table Can Be Updated
The interesting LTAP question is not whether a table can be updated. It is whether fresh writes and analytical reads can share a platform without confusing each other.
The architecture matters because agents compress the time between question, query, interpretation, and action. That matters because a human analyst may notice when a number feels wrong or a dashboard seems delayed. An agent moves through those steps quickly and confidently unless the platform gives it clear freshness and isolation contracts.
The contracts that already mattered now matter more. Write frequency, snapshot visibility, freshness windows, compaction coordination, and serving system boundaries have to be explicit enough for both people and software to rely on them.
What the Specs and Docs Support
The strongest public sources for this topic are the Apache Iceberg specification, Apache Flink documentation, and Apache Kafka documentation. I use those to ground the architecture and avoid treating every June 2026 announcement as a shipped production capability.
The evidence supports a few grounded points:
- Open table formats can support transactional table changes and analytical reads through snapshots.
- Streaming and batch workloads need explicit freshness and isolation contracts.
- LTAP design should distinguish operational serving from analytical decisioning.
That is enough to write a useful technical article. It is not enough to make sweeping claims. I separate released behavior, design direction, and market language because readers can work with careful distinctions. They cannot operate slogans.
The Architecture Pattern
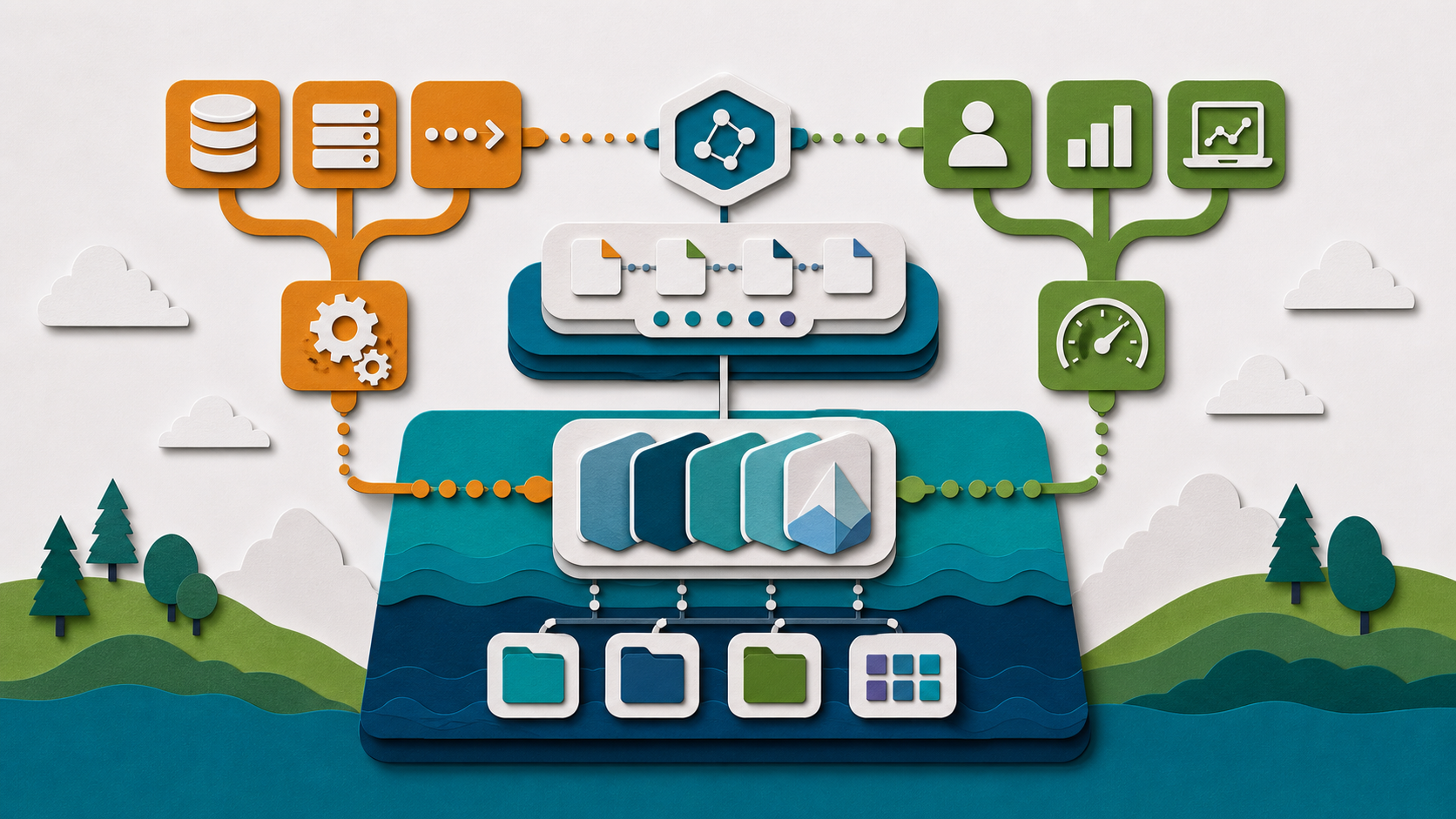
LTAP in the lakehouse sits between two instincts. One instinct says to keep operational and analytical systems separate. The other says to collapse everything into one platform. The useful middle is a set of explicit contracts: which writes are allowed, how quickly they become visible, what readers can assume about snapshot consistency, and which workloads require a serving system instead of an analytical engine.
For this architecture, the five layers worth keeping distinct are storage, catalog, execution, semantics, and agent interface. Storage holds durable files and snapshots. The catalog resolves identity and access. The execution layer plans and runs work. The semantic layer gives business meaning. The agent interface controls which questions and actions are allowed.
The point is not to collapse those layers into one box. The point is to make the handoffs clear. If a user or agent asks for an answer, the platform should be able to explain which table, which snapshot, which definition, which identity, and which policy shaped the result.

A Production-Shaped Example
A good pilot is an event-driven inventory table that receives frequent updates and powers near-real-time analytical dashboards. Define freshness in minutes, not vibes. Define whether readers can tolerate snapshot lag. Define how compaction and maintenance interact with updates. Then measure query latency and correctness during write pressure.
The test should include a happy path and at least three failure paths. One failure should involve access. One should involve stale or incompatible data. One should involve an operational problem: retry behavior, write conflict, or compaction running concurrently with an active reader. Those failures are where the platform either earns trust or loses it.
The test should also produce evidence. Save query IDs, snapshot IDs, freshness timestamps, and write conflict logs. If the team cannot find that evidence after the pilot, the rollout is not ready for a wider audience.
What To Measure
Start with four specific measurements:
- Freshness windows defined and measured in clock time: Confirm that the freshness expectation for each analytical table is written down in minutes or seconds, not described as "near real-time." Real-time means different things to different people. A five-minute freshness window is a contract. "Near real-time" is not.
- Operational serving separated from analytical reads: Measure whether the workloads that need low-latency single-row lookups are routed to a serving system and not competing with analytical query load on the same Iceberg table. If they share compute, measure the latency impact of each on the other.
- Update conflicts tested during compaction: Confirm that the system handles concurrent writes and compaction without silently dropping updates or creating inconsistent snapshots. Track OCC failure rates during heavy write windows.
- Snapshot visibility rules documented and tested: Verify that analytical readers are reading the snapshot they expect. A reader that always reads the latest snapshot may see a partial write. A reader that reads a pinned snapshot may see stale data beyond its freshness window. Both need to be tested, not assumed.
Measurements should connect to decisions. A metric that nobody uses is telemetry decoration.
Common Failure Modes
The first mistake is treating LTAP as a feature checklist. A checklist can confirm that a table can be updated, but it rarely explains how updates behave under concurrent read and write load. The better move is to write the operating contract. Name the freshness window, the write frequency, the snapshot visibility rule, and the compaction schedule before claiming production readiness.
The second mistake is ignoring boundaries. Most LTAP incidents appear where systems meet: writer to catalog, compaction to active reader, streaming ingest to analytical query load. Boundary testing should be part of the rollout. If only the clean write path was tested, the team has not tested production.
The third mistake is hiding tradeoffs behind category language. Words like real-time lakehouse and HTAP can be useful, but they are not a substitute for mechanics. What is the actual freshness window? What is the OCC failure rate under heavy writes? What happens when compaction and ingestion overlap? If the answers are vague, the design is still vague.
The most expensive failures are usually quiet. The analytical dashboard shows a number that is two hours stale because the freshness window was not enforced. The write workload causes planning latency to spike for analytical readers because isolation was not defined. Those failures do not show up as red alerts. They show up as trust problems with the platform.
Guardrails for Agentic Use
Agents should start with certified views, narrow tools, and explicit freshness requirements in tool descriptions. They should not receive write access to LTAP tables unless the workflow has explicitly been designed for agentic writes with conflict handling and rollback logic.
I would also require a visible refusal path. If data is outside the freshness window, the agent should say so. If the write would conflict with an active compaction job, the agent should defer. A graceful refusal is not a bad user experience. It is a trust feature.
Operational Checklist
| Area | Question to answer | Why it matters |
|---|---|---|
| Ownership | Who owns the table, the write pipeline, and the compaction schedule? | Incidents need named owners, not shared confusion. |
| Freshness | What is the defined freshness window for each analytical table? | Freshness without a number is not a contract. |
| Isolation | Which write and read workloads are isolated from each other? | Write pressure should not degrade analytical latency. |
| Evidence | Which snapshot IDs, freshness timestamps, and conflict logs are saved? | Trust needs a trail. |
| Rollback | What happens when a write conflict or compaction failure occurs? | Recovery is part of the design, not an afterthought. |
This checklist is intentionally plain. The hard part is not inventing a complex LTAP framework. The hard part is answering the simple questions before users and agents depend on the freshness contract.

What Engineers Should Verify
Engineers should verify exact engine versions, write conflict behavior, snapshot visibility rules, compaction coordination, and freshness measurement. Claiming "LTAP support" is not enough. The team needs to know which write patterns were tested, which read patterns were validated under write load, and which scenarios are explicitly out of scope.
The practical test is simple: can another engineer reproduce the setup, trigger a write conflict during compaction, understand the logs, and confirm that the analytical reader saw the correct snapshot? If not, the LTAP contract is not verified.
The setup should also be tested under realistic concurrency: streaming ingestion, batch updates, analytical queries, and compaction all running simultaneously. Many LTAP designs look correct in isolation. They reveal problems under simultaneous load.
What Data Owners Should Verify
Data owners should verify that the freshness window they defined is actually enforced and measured. A data owner who said "five minutes" and a platform that delivers "fifteen minutes with no warning" have a gap that will eventually cause a trust problem.
This review should happen before agent exposure. If an agent reads a table under the assumption that it is fresh within five minutes, and the actual freshness is twenty minutes, the agent will give confident but stale answers. That is a design gap, not a model problem.
Data owners should also decide which workloads need a dedicated operational serving system rather than direct Iceberg access. Not every use case is a good fit for a unified analytical and operational surface. Some low-latency lookups belong in a purpose-built serving tier.
What Executives Should Hear
The summary should be plain: LTAP in the lakehouse reduces the number of system copies when teams can define clear freshness and isolation contracts. It is risky when freshness is assumed rather than measured, or when operational and analytical workloads compete without isolation.
The value is fewer data copies, cleaner operational semantics, and a platform that can support both operational freshness and analytical depth from the same table. The limit is that the platform cannot eliminate the need for freshness contracts, quality checks, and compaction schedules.
Executives should also hear that LTAP is a design pattern that requires ongoing operational discipline. It is not a one-time migration.
A Good First Rollout
Start with one high-frequency update table in a non-critical domain. Define the freshness window. Define the isolation boundaries. Define the snapshot visibility rule. Test write and read workloads simultaneously. Measure.
Define success with three outcomes. The first is correctness: analytical reads always reflect the expected freshness window. The second is isolation: write workloads do not degrade analytical query latency beyond an acceptable threshold. The third is operability: write conflicts and compaction collisions are logged and recoverable.
After that, expand to another table or a higher write frequency. Expanding one dimension at a time is slower than a sweeping rollout, but it creates fewer freshness surprises.
Deeper Design Notes
The design work should begin with the nouns in the LTAP workflow. Name the tables, freshness windows, write frequencies, snapshot visibility rules, compaction schedules, and failure states. When those nouns are vague, every later discussion becomes vague too. Start with the concrete contracts and build outward.
The next step is to define the dimensions that actually change behavior: fresh writes, analytical reads, snapshot visibility, streaming ingestion frequency, and compaction coordination. These are not decorative details. They determine whether the system is predictable under real use.
Review Questions Worth Asking
The first question: what is the freshness window for each table that is part of this rollout, measured in clock time? If the answer is "as fresh as possible," the contract is not defined.
The second question: what happens when a heavy write window and a compaction job overlap on the same partition? If the answer is unclear, the rollout is not ready for production write patterns.
The third question: who gets notified when the freshness window is breached? If the answer is "nobody," the monitoring is not ready. Freshness contracts without enforcement are just documentation.
A Realistic Pilot Shape
A realistic pilot should look like an inventory table updated frequently by a Flink streaming job and queried by operational dashboards through an analytical engine. That scenario is narrow enough to test and broad enough to reveal freshness and isolation problems. It should include one clean read during normal writes, one read during a compaction job, one write conflict, and one freshness window breach. The point is not to make the pilot impressive. The point is to make it diagnostic.
Include a repetition test. Run the same write and read patterns across several days with varying ingestion rates. Many LTAP designs work at low write frequency. They reveal isolation problems when write volume spikes.
Metrics That Should Drive the Next Decision
The first metrics to watch are freshness lag versus the defined window, write conflict rate, compaction collision frequency, and analytical query latency under write load. Those measurements should lead to a decision about whether to expand, tune isolation, adjust compaction schedules, or move a workload to a dedicated serving tier.
A second group of metrics should track trust: how often did the platform deliver data within the freshness window? How often did analytical readers notice stale data? Those signals matter because trust in an LTAP platform is built on freshness consistency, not peak performance.
A third group should track cost: how much does the compaction schedule cost relative to query performance improvements? There is a real cost tradeoff between compaction frequency and write performance. Track both sides.
What I Would Cut From a Weak Rollout
Cut operational serving from the first LTAP phase. Single-row, low-latency lookups belong in a serving tier. Adding them to the first LTAP pilot makes it harder to understand what is causing latency when things slow down.
Cut write-heavy workloads from the initial analytical surface until isolation is verified. Start with tables that have moderate write frequency where freshness windows are achievable. Add high-frequency write tables after the isolation model is proven.
Cut compaction during business hours from the first phase. Schedule compaction during off-peak windows until the interaction between compaction and active readers is well-understood.
The Practical Standard
The practical standard for LTAP is not perfection. It is freshness within the defined window, isolation between write and read workloads, and explainability when something goes wrong. When a dashboard shows a number that seems stale, an operator should be able to pull up the freshness log and confirm whether the window was respected.
That standard is demanding, but it is realistic. It lets teams unify analytical and operational workloads without pretending that the platform eliminates the need for careful operational design.
My Recommendation
Take LTAP in the lakehouse seriously, but do not oversell it. The useful bar is simple: can the team define the freshness window, measure it continuously, isolate write and read workloads, and recover from write conflicts?
If the answer is yes, the pattern deserves a production pilot. If the answer is no, the next step is not a bigger announcement. The next step is a clearer freshness contract.
Dremio fits the LTAP conversation when the discussion is about fast governed analytics on open tables, not about replacing every operational database. The architecture point stands regardless of platform: when teams define freshness, isolation, and workload boundaries clearly, the lakehouse can serve both analytical and operational needs without the friction of separate systems.
For a deeper foundation on lakehouse and AI architecture, explore Alex Merced's books on data lakehouses and AI at books.alexmerced.com. To try a governed, open, agent-ready lakehouse in practice, start a free trial of Dremio's Agentic Lakehouse at dremio.com/get-started.