PyIceberg at Scale Without Apache Spark

PyIceberg at Scale Without Apache Spark
Python-first Iceberg work is useful when it stays honest about what Python should and should not do. For Python data engineers and platform teams, the useful question is what changes in production and what simply sounds current.
Serverless Functions Can Append Small Batches, but 20 TB Backfills Still Belong on Proper Engines
A serverless function can validate schema and append small batches, but a 20 TB historical backfill should run on a proper execution engine.
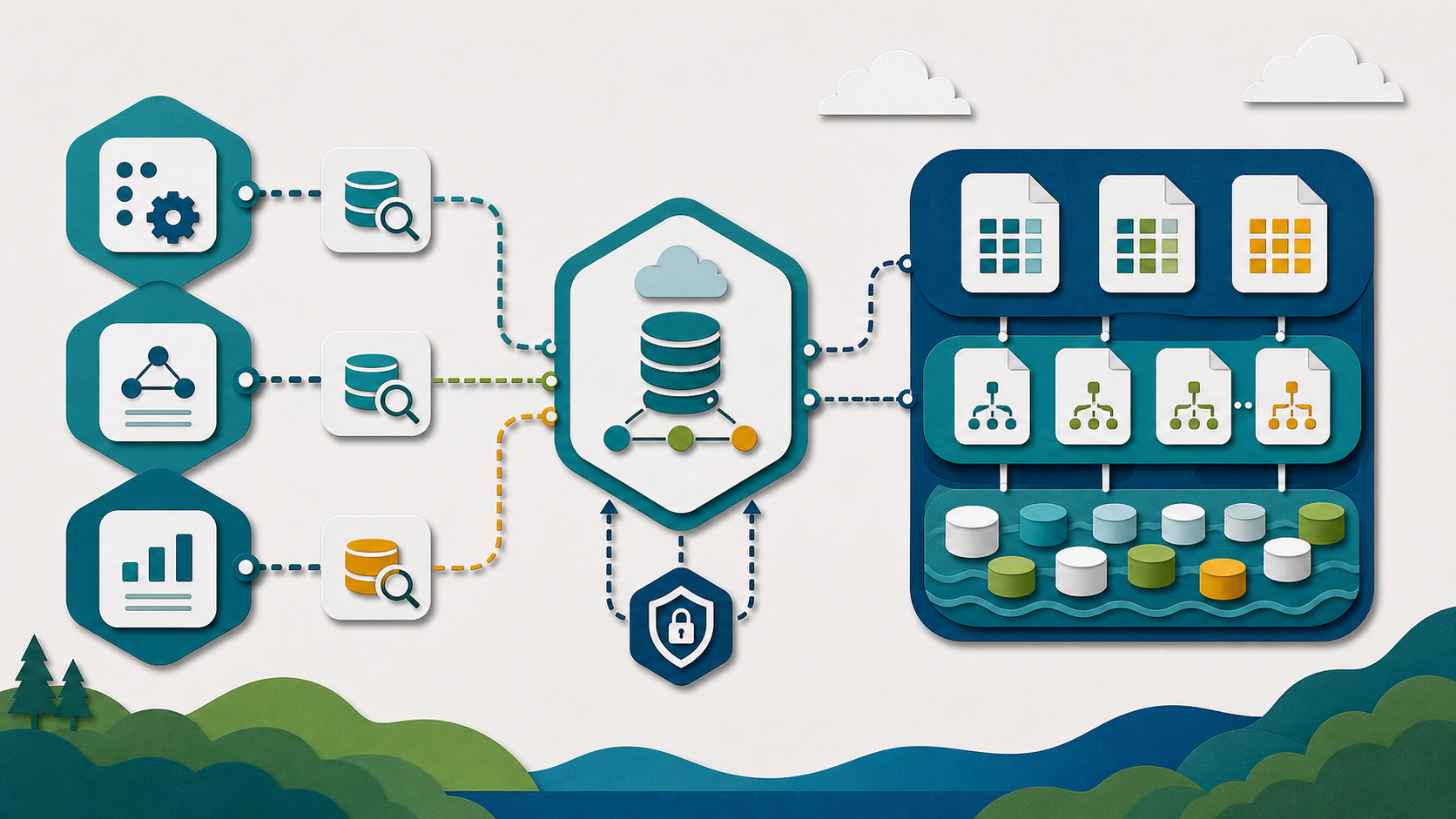
This is where Python's role in the lakehouse becomes useful to define clearly. Python is attractive because it is close to orchestration, tests, APIs, and lightweight services. That proximity does not make Python the right execution engine for every workload. The clean design is to use PyIceberg for table metadata, schema evolution checks, small controlled writes, and automation around catalogs. Heavy analytical reads and broad rewrites should use engines built for parallel execution.
The contracts that already mattered now matter more. Workload boundaries, commit idempotency, concurrency limits, and connection management have to be explicit enough for both people and software to rely on them.
What the Docs Support
The strongest public sources for this topic are PyIceberg documentation, the Apache Iceberg specification, and the Apache Iceberg REST catalog specification. I use those to ground the architecture and avoid treating every June 2026 announcement as a shipped production capability.
The evidence supports a few grounded points:
- PyIceberg is useful for catalog operations, metadata inspection, schema work, and targeted pipelines.
- High-concurrency serverless workloads need connection management and idempotent commit handling.
- Heavy scans still belong on engines designed for distributed execution unless measured otherwise.
That is enough to write a useful technical article. It is not enough to make sweeping claims. I separate released behavior, design direction, and market language because readers can work with careful distinctions. They cannot operate slogans.
The Architecture Pattern
Python is attractive because it is close to orchestration, tests, APIs, and lightweight services. That does not make Python the right execution engine for every workload. The clean design is to use PyIceberg for table metadata, schema evolution checks, small controlled writes, and automation around catalogs. Heavy analytical reads and broad rewrites should use engines built for parallel execution.
For this architecture, the five layers worth keeping distinct are storage, catalog, execution, semantics, and agent interface. Storage holds durable files and snapshots. The catalog resolves identity and access. The execution layer plans and runs work. The semantic layer gives business meaning. The agent interface controls which questions and actions are allowed.
The point is not to collapse those layers into one box. The point is to make the handoffs clear. If a user or agent asks for an answer, the platform should be able to explain which table, which snapshot, which definition, which identity, and which policy shaped the result.
A Production-Shaped Example
A good production pattern is a Python service that validates incoming schema, resolves the table through a REST catalog, writes a small batch, and records the snapshot it produced. A separate query engine handles large scans, user-facing SQL, and acceleration. That split keeps Python useful without turning it into an accidental replacement for distributed compute.
The test should include a happy path and at least three failure paths. One failure should involve access. One should involve stale or incompatible data. One should involve an operational problem: retry behavior, OCC failure, or catalog connection exhaustion under high concurrency. Those failures are where the platform either earns trust or loses it.
The test should also produce evidence. Save snapshot IDs, commit outcomes, catalog response times, and validation output. If the team cannot find that evidence after the pilot, the rollout is not ready for a wider audience.
What To Measure
Start with four specific measurements:
- Commit idempotency under retry: Confirm that when a PyIceberg write is retried after a network failure, it does not produce duplicate data or orphaned files. Idempotency requires that the writer checks for an existing commit that matches the expected outcome before issuing a new one. This is the most critical correctness property for serverless Python pipelines.
- Serverless worker concurrency and catalog connection pool: Track how many concurrent PyIceberg workers are hitting the REST catalog simultaneously. The catalog is a shared resource. Too many concurrent connections will cause latency spikes or failures. Set explicit connection limits and measure catalog response time under the maximum expected concurrency.
- Large scan operations routed away from Python workers: Confirm that queries that scan more than a defined threshold of files or partitions are routed to an execution engine rather than running through PyIceberg. Track the percentage of queries that exceed the threshold and verify they do not slip through to the Python path.
- Snapshot IDs recorded in operational logs: Verify that every PyIceberg write operation records the snapshot ID it produced. That snapshot ID is the rollback handle. Without it, recovering from a bad write requires manual catalog inspection.
Measurements should connect to decisions. A metric that nobody uses is telemetry decoration.
Common Failure Modes
The first mistake is treating PyIceberg as a general-purpose query engine. It is not. It is useful for catalog operations, small writes, and metadata work. Teams that use PyIceberg for full-table scans of large datasets will encounter memory problems and slow performance that a distributed engine would handle correctly.
The second mistake is ignoring catalog connection limits. A serverless environment that spins up hundreds of concurrent PyIceberg workers will exhaust the REST catalog's connection pool. That is not a catalog bug. It is a design gap in the Python layer. Connection pooling, worker limits, and retry backoff are engineering requirements, not afterthoughts.
The third mistake is non-idempotent writes. A Python worker that writes and then fails before recording its snapshot ID creates ambiguity: did the write commit or not? The next retry may duplicate data. Designing for idempotent commits from the start avoids that class of problem entirely.
The most expensive failures are usually quiet. The small file count grows because Python workers write one file per event instead of batching. The catalog connection pool slowly degrades under load without anyone noticing until it fails. The rollback path does not work because snapshot IDs were never recorded. Those failures do not show up as red alerts. They show up as slow queries and unexplained data issues weeks later.
Guardrails for Agentic Use
Python-based agentic workflows should start with narrow, well-defined write operations: schema validation, small batch commits, catalog metadata reads. They should not receive broad write authority over large tables.
I would also require a visible refusal path for agentic Python writers. If the write would exceed the batch size limit, the agent should defer to an execution engine. If the commit fails after retries, the agent should record the failure with the attempted snapshot state, not silently proceed. A graceful limitation is not a bad user experience. It is a trust feature.
Operational Checklist
| Area | Question to answer | Why it matters |
|---|---|---|
| Ownership | Who owns the table, catalog path, and write pipeline? | Incidents need named owners, not shared confusion. |
| Scope | Which write operations are in scope for Python workers? | A narrow scope prevents Python from doing work it should not. |
| Concurrency | What is the maximum concurrent worker count hitting the catalog? | Connection exhaustion needs an explicit limit. |
| Evidence | Which snapshot IDs and commit outcomes are saved? | Rollback requires a paper trail. |
| Rollback | What happens when a commit fails or produces unexpected data? | Recovery is part of the design, not an afterthought. |
This checklist is intentionally plain. The hard part is not inventing a complex Python-Iceberg framework. The hard part is defining the workload boundary before a large scan accidentally runs in a small Python worker.
What Engineers Should Verify
Engineers should verify exact PyIceberg versions, REST catalog API compatibility, commit idempotency under retry, catalog connection behavior under concurrency, and snapshot recording in operational logs. Claiming "PyIceberg at scale" is not enough. The team needs to know which workload sizes were tested, which failure paths were verified, and which scenarios are explicitly out of scope for Python workers.
The practical test is simple: can another engineer reproduce a failed write scenario, verify that the retry did not duplicate data, and confirm the rollback path using only the operational logs? If not, the pipeline is not production-ready.
The setup should also be tested under realistic concurrency: many workers hitting the catalog simultaneously during a high-ingest window. Most PyIceberg pipelines work correctly under low load. Production readiness requires the high-concurrency case.
What Data Owners Should Verify
Data owners should verify that the freshness expectations and ownership rules for tables written by PyIceberg workers are defined and enforced. A Python pipeline that writes to a production table without a named owner and a defined freshness window is an ungoverned write path.
This review should happen before agentic Python writers are deployed. If a Python agent can write to a table, data owners should confirm the write schema, the batch size policy, and the quality check that runs after each commit.
What Executives Should Hear
The summary should be plain: PyIceberg is a useful tool for Python teams that need direct table access without a JVM dependency. It is most valuable for catalog operations, schema work, and small controlled writes. It is not a replacement for distributed query engines for large analytical workloads.
The value is flexibility and developer productivity for Python teams. The limit is that Python workers have memory and concurrency constraints that distributed engines do not. Workload routing is the engineering discipline that makes PyIceberg production-safe.
A Good First Rollout
Start with one table and one write pattern: schema validation and small batch commits from a Python service. Define the batch size limit. Define the connection pool size. Define idempotency behavior. Test under the expected concurrency. Record snapshot IDs.
Define success with three outcomes. The first is correctness: retry does not produce duplicate data. The second is safety: large scan requests are refused or routed to an execution engine. The third is operability: snapshot IDs and commit outcomes are recorded and queryable.
After that, expand to other tables or other Python workflows. Expanding one dimension at a time is slower than a sweeping rollout, but it creates fewer concurrency surprises.
Deeper Design Notes
The design work should begin with the workload boundary. Name the operations that belong in Python (schema validation, small writes, catalog reads, metadata automation) and the operations that belong in a distributed engine (full table scans, broad rewrites, large aggregations). When that boundary is vague, Python workers end up doing work they should not, and the platform suffers for it.
The next step is to define the dimensions that actually change behavior: batch size, concurrency limit, connection pool size, retry policy, and snapshot recording. These are not decorative details. They determine whether the Python pipeline is safe under real load.
Review Questions Worth Asking
The first question is simple: what is the maximum batch size and concurrency limit for Python writers on this table? If the answer is "unlimited," the pipeline is not production-ready.
The second question: what happens when a Python write fails after the first OCC conflict? If the retry logic is not idempotent, the answer to this question reveals a potential data duplication risk.
The third question: who gets notified when the catalog connection pool is exhausted or when retry counts exceed the limit? If the answer is unclear, the pipeline has no operational escalation path.
A Realistic Pilot Shape
A realistic pilot should look like a serverless Python service processing incoming events, validating schema, and appending small batches to an Iceberg table through a REST catalog. The pilot should include one clean write, one retry after a simulated network failure, one batch that exceeds the size limit and is refused, and one catalog connection pool saturation scenario. The point is not to make the pilot impressive. The point is to make it diagnostic.
Include a repetition test. Run the same pipeline across several days with varying event volumes. Many Python-Iceberg pipelines work correctly at low volume. They reveal connection and concurrency problems under production load.
Metrics That Should Drive the Next Decision
The first metrics to watch are commit idempotency verification rate, catalog connection pool utilization, snapshot ID recording rate, and large-scan-to-engine routing rate. Those measurements should lead to a decision about whether to expand the pipeline, tighten concurrency limits, improve rollback procedures, or route more work to a distributed engine.
A second group of metrics should track cost: how much catalog connection and object storage API cost does the Python pipeline generate? Small writes that are not batched can generate surprising catalog overhead.
A third group should track reliability: how often does the retry logic succeed versus fail? High retry failure rates signal that the concurrency or OCC configuration needs adjustment.
What I Would Cut From a Weak Rollout
Cut full-table scans from Python workers first. If a scan is large enough to benefit from predicate pushdown across many files, it belongs on an execution engine.
Cut unrecorded snapshot IDs. Any write operation that does not produce a recorded snapshot ID is not recoverable without manual catalog inspection.
Cut unlimited concurrency. Define the maximum worker count before deployment. Unlimited concurrency is a catalog connection pool problem waiting to happen.
The Practical Standard
The practical standard for Python-first Iceberg work is not maximum throughput. It is safe, idempotent, observable operation within defined workload boundaries. When a write fails, the snapshot ID should be in the log. When retries happen, data should not be duplicated. When the batch is too large, the pipeline should refuse and route elsewhere.
That standard is demanding, but it is realistic. It lets Python teams use PyIceberg in production without pretending that Python removes the need for execution engine design.
My Recommendation
Take PyIceberg at scale seriously for the right workloads, but do not oversell it. The useful bar is simple: can the team define the workload boundary, enforce idempotency, manage concurrency, and record every commit's snapshot ID?
If the answer is yes, the pattern deserves a production pilot. If the answer is no, the next step is not a bigger announcement. The next step is a cleaner workload boundary.
PyIceberg is complementary to platforms like Dremio rather than competitive with them. Python can handle metadata-aware automation and small controlled writes, while Dremio can provide governed SQL, semantic views, and acceleration over the same open tables. The two tools do different jobs on the same data foundation.
For a deeper foundation on lakehouse and AI architecture, explore Alex Merced's books on data lakehouses and AI at books.alexmerced.com. To try a governed, open, agent-ready lakehouse in practice, start a free trial of Dremio's Agentic Lakehouse at dremio.com/get-started.