What is Apache Polaris? Unifying the Iceberg Ecosystem
Read the complete Open Source and the Lakehouse series:
- Part 1: Apache Software Foundation: History, Purpose, and Process
- Part 2: What is Apache Parquet?
- Part 3: What is Apache Iceberg?
- Part 4: What is Apache Polaris?
- Part 5: What is Apache Arrow?
- Part 6: Assembling the Apache Lakehouse
- Part 7: Agentic Analytics on the Apache Lakehouse
Treating thousands of Parquet files as a unified database table requires a brain. Apache Iceberg provides the metadata structure to do this, but the Iceberg specification alone does not spin up a server, manage security roles, or handle network requests. You need a catalog service to orchestrate those root metadata pointers.
Until recently, that catalog layer threatened to fragment the entire lakehouse vision. Vendors began building their own proprietary catalogs to track Iceberg tables, trapping users in the exact data silos Iceberg promised to eliminate. Apache Polaris solves that fracture.
The Catalog Fragmentation Problem
Apache Iceberg ensures you do not have to copy data from Amazon S3 to Azure or Google Cloud just to query it. But if the pointer deciding which file is the "current" version of a table lives inside a vendor-locked ecosystem, engine independence becomes a myth.
If your data ingestion pipeline uses Apache Flink writing to a proprietary catalog, your business intelligence tool querying via Apache Trino or Dremio cannot see those updates unless they share the exact same catalog protocol.
The industry realized that to maintain true decoupling of compute and storage, the catalog itself had to become an open standard. That standard materialized as the Iceberg REST Catalog API.
The Iceberg REST API Standard
Apache Polaris is a vendor-neutral, open-source backend implementation of the Iceberg REST Catalog specification.
Because Polaris strictly adheres to the REST spec, any compute engine that speaks Iceberg REST can connect to it. A Spark job can create a table, a Flink job can stream records into it, and a Dremio cluster can instantly query the results.

This architecture guarantees true interoperability. Polaris becomes the single source of truth for your lakehouse. It tracks the latest metadata pointers and ensures that concurrent read and write operations across different engines maintain transactional consistency.
Enterprise Security with Credential Vending
Centralizing metadata also centralizes security. If multiple disconnected engines access the same object storage bucket, managing cloud identity roles becomes a nightmare of overly broad permissions.
Polaris implements robust Role-Based Access Control (RBAC) to solve this. Administrators define access policies for individual catalogs, namespaces, and tables directly inside Polaris. When an analyst runs a query on an engine, they don't use their own cloud credentials.

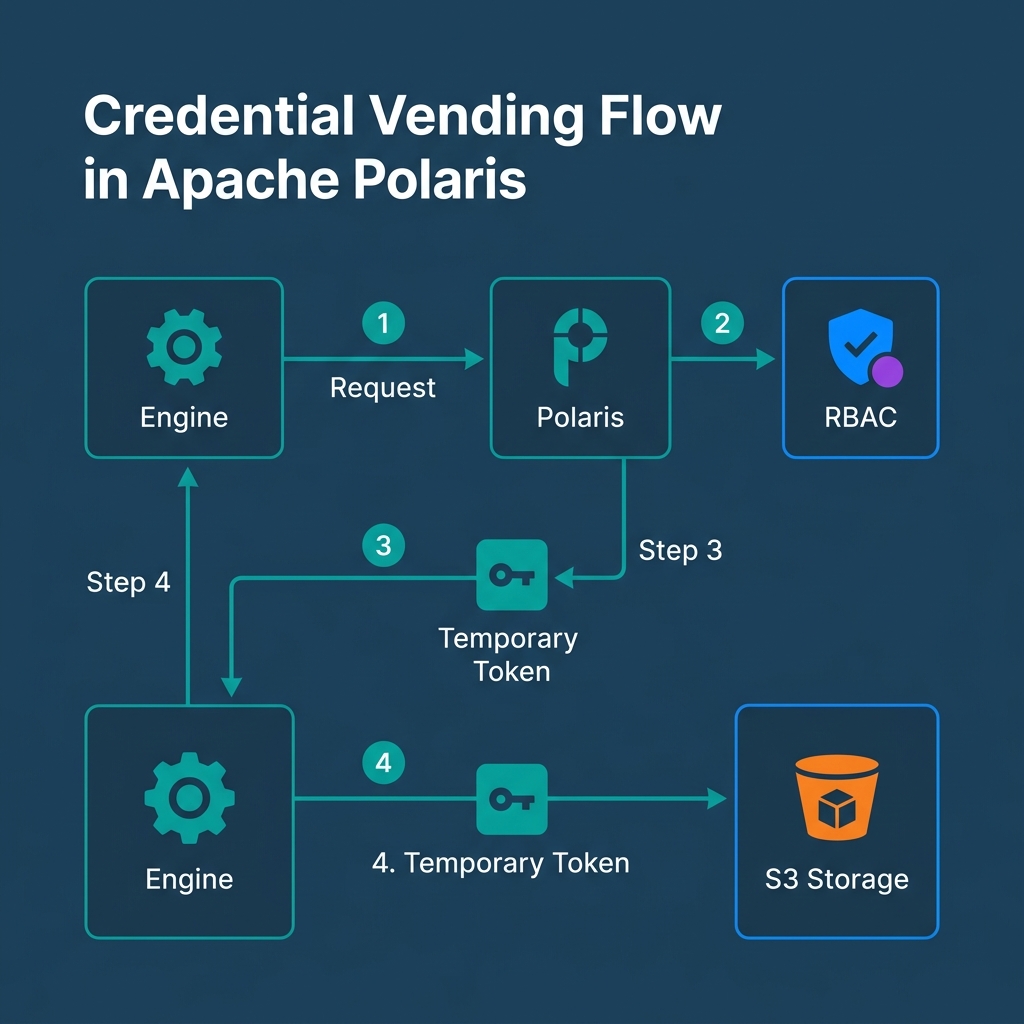
Instead, Polaris utilizes Credential Vending. The engine asks Polaris for access to a table. Polaris verifies the user's RBAC privileges. If approved, Polaris vends a temporary, highly scoped security token back to the engine. The engine uses that temporary token to read the specific Parquet files from S3. This eliminates the risk of issuing permanent, root-level S3 access keys across dozens of compute clusters.
Guaranteed Vendor Neutrality Under the ASF
A catalog is the brain of the lakehouse. If a single vendor owns the code running that brain, they quietly control the lakehouse. They dictate the roadmap, licensing, and integration pace.
By donating Polaris to the Apache Software Foundation as an incubating project, the ecosystem legally shielded its interoperability. Open governance guarantees that Polaris remains neutral territory. No single cloud provider or query engine vendor can monopolize the definition of your table metadata.

The Evolving Architecture
If Apache Parquet provides the high-performance storage disk, and Apache Iceberg acts as the relational file system, Apache Polaris serves as the brain resolving engine traffic and access control. Together, they form the foundation of a modern data architecture.
Dremio’s built-in Open Catalog is built natively on Apache Polaris. When you sign up, you get a production-ready, vendor-neutral Polaris catalog deployed instantly. Try Dremio Cloud free for 30 days to query your data without creating proprietary metadata silos.