Data Mesh After the Hype: What Actually Works
Data Mesh After the Hype: What Actually Works
When Zhamak Dehghani published the original data mesh papers at Thoughtworks in 2019 and 2020, the response split sharply between organizations that saw it as a fundamental rethinking of data platform architecture and skeptics who viewed it as a repackaging of existing domain-driven design concepts applied to data teams.
Both groups were partially right. The conceptual insight in data mesh — that the bottleneck in enterprise data platforms is organizational, not technical, and that treating data as a product published by domain teams addresses scaling problems that no amount of centralized engineering can solve — was valuable and largely correct. The implementation turned out to be significantly harder and more context-dependent than the original framing suggested.
Three years of production data mesh implementations across organizations of various sizes have produced a clearer picture of what works, what doesn't, and where "data product thinking" delivers value without requiring a full organizational reorganization.
The Four Principles, Revisited
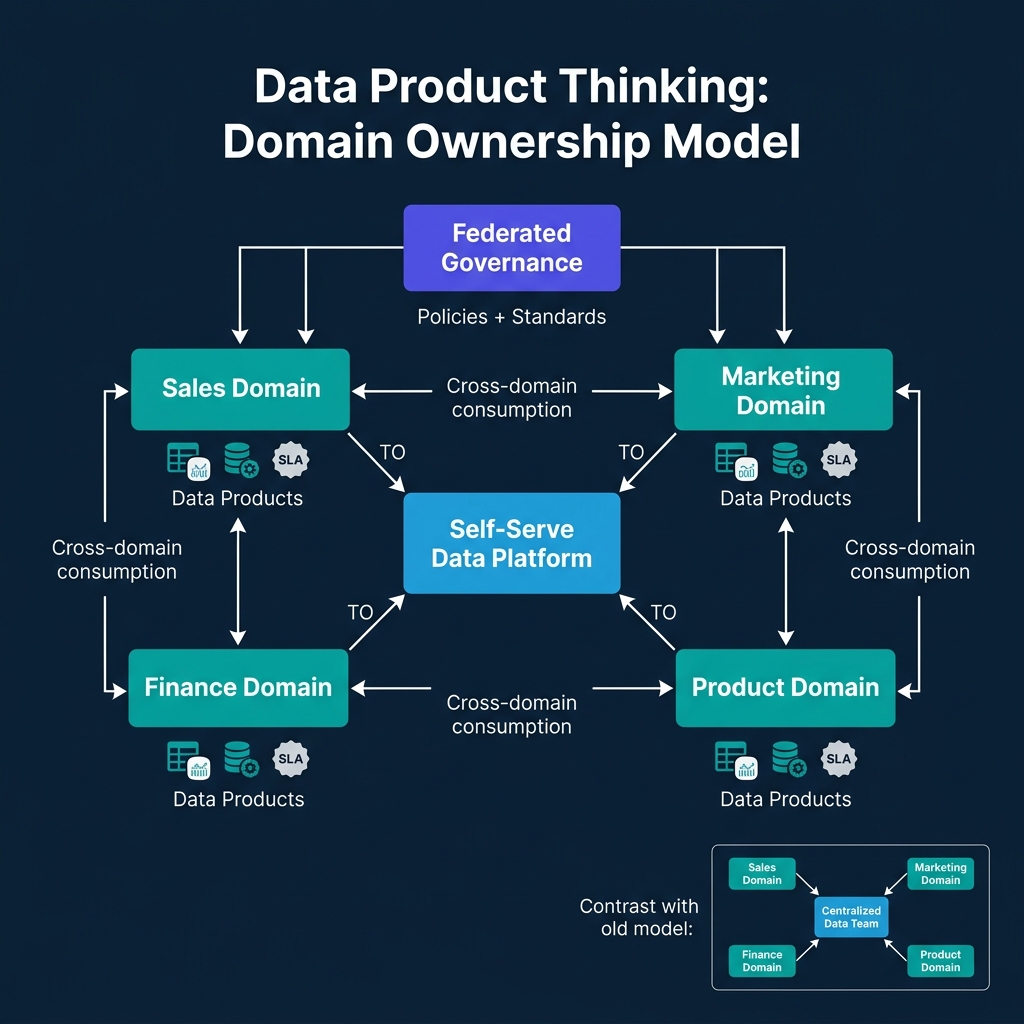
Data mesh's four core principles are:
- Domain ownership: Teams own their data, end-to-end, from ingestion through publication
- Data as a product: Domains publish data products with explicit quality contracts
- Self-serve platform: Infrastructure for building, publishing, and consuming data products is shared
- Federated governance: Policy enforcement is distributed but consistent
In practice, most organizations that have successfully adopted data mesh patterns have implemented principles 2 and 3 first, without requiring full domain ownership (principle 1) or complex federated governance mechanisms (principle 4). This partial adoption has delivered real value without the organizational disruption of a full mesh topology.
What Domain Ownership Actually Requires
Full domain ownership — where a domain team handles their own ingestion, transformation, quality monitoring, and publication — requires those teams to have (or develop) data engineering competency. For organizations where data engineering is scarce, asking a sales team or a product team to also manage their Spark jobs and Iceberg table maintenance is unrealistic.
The organizations that have made domain ownership work share two characteristics: they have a strong self-serve data platform (principle 3 genuinely delivers on its promise, so domain teams aren't managing infrastructure directly), and they have embedded or dedicated data engineers within domain teams who handle the technical implementation.
For organizations without these conditions, "domain ownership" typically degrades to "domain teams declare what data they want published" while a central data engineering team does the actual implementation. This is a useful organizational pattern, but it's not what the original mesh architecture describes.
Data Products: The Most Adoptable Principle
The most universally valuable data mesh concept is treating datasets as products. A data product has:
- Defined ownership (a team, with named contacts)
- Documented schema and semantics (what does each column mean?)
- SLA commitments (freshness, availability, quality thresholds)
- Access controls (who can read what)
- Discovery metadata (searchable in a catalog)
This discipline — treating published datasets as products rather than pipeline outputs — improves data quality and consumer trust regardless of whether the organization adopts the full mesh topology.
The key governance artifact for data products is a quality contract:
# data_product_contract.yaml
name: customer_360
owner: "data-engineering-platform@company.com"
domain: "customer"
version: "2.3.0"
schema:
- field: customer_id
type: STRING
description: "Unique customer identifier (UUID format)"
nullable: false
- field: lifetime_value
type: DECIMAL(18,2)
description: "Cumulative purchase value in USD since account creation"
nullable: true
quality_sla:
freshness_minutes: 60 # Updated at most 60 minutes ago
completeness_threshold: 0.99 # 99% of expected records present
null_rate_threshold: # Column-level null rate limits
customer_id: 0.0
lifetime_value: 0.05
access_control:
default_access: "INTERNAL"
readers:
- role: "analyst"
filter: "region = current_user_attribute('region')"
- role: "data_scientist"
filter: null # Full access
discovery:
tags: ["customer", "crm", "pii-contains"]
lineage: "sourced from salesforce_sync + product_events"When a data product has a contract like this, consumers know what they're getting. Engineers publishing the product have measurable SLAs to maintain. Monitoring tools can alert when the product violates its contract. This is a significant improvement over the typical enterprise data catalog experience where datasets exist but quality commitments are informal at best.
The Bottleneck Data Mesh Actually Solves
The organizational problem data mesh addresses is the centralized data team bottleneck. When all data engineering work — ingestion, transformation, quality monitoring, publication — flows through a central team, that team becomes a bottleneck. Domain teams wait weeks for data pipeline requests. The central team lacks domain context and builds suboptimal transformations. Priority conflicts between domains are constant.

Domain ownership addresses this by moving pipeline ownership to the teams with the domain context. A finance team that owns their own data pipelines can prioritize, design, and maintain those pipelines without waiting for a central team's ticket queue. The tradeoff is distributed responsibility — the central platform team maintains the self-serve infrastructure, while domain teams maintain their pipelines.
For organizations with 50+ data pipelines spanning 10+ domains and a central data engineering team perpetually backlogged, the mesh topology is worth the organizational investment. For organizations with 10 pipelines and a data engineering team of five, a well-run centralized team with good domain partnership is more practical.
The Self-Serve Platform: The Hard Part
Data mesh's least-examined principle — and the one that most implementations underinvest in — is the self-serve platform. For domain ownership to work without requiring each domain to have full-stack data engineering expertise, the platform must make it easy to:
- Ingest data from common sources (Salesforce, Postgres, Kafka) without writing Spark jobs
- Transform data using SQL with managed orchestration (dbt on Airflow)
- Publish data products with automatic quality monitoring
- Register products in a searchable catalog with governance metadata
- Monitor pipeline health without deep infrastructure knowledge
Building this platform is significant engineering work. Organizations that adopt domain ownership without investing in the self-serve platform discover that domain teams default to doing things the way they've always done them — ad-hoc pipelines, no quality contracts, no catalog registration — because the "easy path" doesn't exist.
Pragmatic Data Product Thinking
The practical takeaway from three years of data mesh implementation experience is that the product mindset is the most valuable element, and it can be adopted incrementally:
- Start with ownership: Every dataset has a named owner who is accountable for its quality and freshness.
- Add contracts: Each published dataset has a written quality contract with freshness and completeness SLAs.
- Build discoverability: Datasets are registered in a catalog with enough metadata for consumers to find and evaluate them.
- Enforce governance: Access controls, audit logs, and lineage tracking are automatic, not manual.
This progression delivers data product value without requiring the full organizational topology change of a complete mesh. Teams that have never experienced domain ownership can start with ownership accountability and contracts, build the discipline, and expand from there.
Conclusion
Data mesh as a philosophy — treat data as a product, distribute ownership to domain teams, invest in self-serve infrastructure, federate governance — has proven valuable in organizations with the right scale and organizational conditions. As a rigid implementation requirement, it has proven impractical for smaller organizations and those without self-serve infrastructure investment.
The durable insight is data product thinking: explicit ownership, quality contracts, discoverability, and governance. These disciplines improve data platform reliability and consumer trust regardless of whether the organization adopts a full mesh topology.
Common Failure Modes in Data Mesh Implementations
Organizations that attempted full data mesh adoption and struggled share common patterns. Understanding these failure modes helps set realistic expectations and avoid the most costly mistakes.
Failure Mode 1: Adopting the topology without the platform. Domain ownership requires domain teams to have the tools to build, test, and publish data pipelines without central team support. When organizations announce domain ownership without first building the self-serve platform, domain teams either revert to requesting help from the central team (recreating the bottleneck) or build ad-hoc pipelines without quality controls (creating new technical debt).
Failure Mode 2: Data product contracts without enforcement. Writing a quality contract is easy. Monitoring compliance with the contract and alerting when products violate their SLAs requires tooling investment. Organizations that create contract documentation but don't build automated monitoring discover that contracts become stale and untrustworthy, undermining consumer confidence in the entire data product catalog.
Failure Mode 3: Federated governance without standards. Federated governance means each domain sets their own policies within organizational bounds. Without clear organizational standards (what tags are required, what sensitivity classifications exist, what the audit log format is), domain policies diverge. Cross-domain data product consumption becomes complicated by inconsistent access patterns and incompatible metadata schemas.
Failure Mode 4: Mesh topology without domain data engineering capacity. The hardest organizational constraint is finding engineers who have both data engineering skills and deep domain knowledge. Most organizations don't have enough of these people, and training existing engineers takes time. Rushing domain ownership before teams have the technical capacity produces low-quality pipelines with no quality monitoring.
The Data Catalog as Connective Tissue
A searchable, accurate data catalog is the organizational glue that makes federated data products usable. Without it, data products exist in isolated silos — the finance team knows about the finance data products, the marketing team knows about their products, but cross-domain discovery requires personal relationships rather than tooling.
Modern data catalogs like Datahub, Alation, Atlan, and Apache Atlas provide:
Semantic search: Search for data products by business concept, not technical names. "Find data products containing customer lifetime value" should return relevant datasets without requiring knowledge of how the finance team named their clv_90d column.
Lineage visualization: Click on a data product in the catalog and see its upstream sources (which pipelines write to it) and downstream consumers (which dashboards, models, and pipelines read from it). This cross-domain lineage view is only possible if OpenLineage events from each domain's pipelines flow to the shared catalog.
Ownership and contact information: Every catalog entry shows the owning team and a contact mechanism. When a consumer discovers that a data product's quality has degraded, they know immediately who to contact.
Quality signals: The catalog integrates data quality monitoring alerts, showing consumers whether a data product currently meets its SLA. A red quality indicator on a catalog entry tells consumers not to rely on the product until the owner resolves the underlying issue.
Investing in the catalog before scaling domain ownership is one of the highest-leverage decisions an organization can make. It creates the shared vocabulary and discoverability infrastructure that makes cross-domain data product consumption possible.
Measuring Data Mesh Success
The organizational investment in data mesh should be measured against concrete outcomes. Useful metrics for evaluating data mesh maturity and effectiveness:
Data product SLA compliance rate: What percentage of data products meet their freshness and completeness SLAs? A well-functioning mesh should maintain >95% compliance across products. Declining compliance rates indicate either inadequate monitoring, insufficient domain team capacity, or over-committed SLAs.
Time to data product: How long does it take from "this domain needs a new data product" to "the product is published and available to consumers"? In a centralized team model, this is often measured in weeks (waiting for engineering capacity). In a functioning mesh, it should be days for typical products.
Cross-domain consumption rate: How many data products are consumed by domains other than their producer? Low cross-domain consumption suggests the catalog isn't surfacing relevant products, or that consumers don't trust products from other domains. High cross-domain consumption is evidence that the mesh is creating organizational value beyond siloed domain analytics.
Unattributed pipeline ownership: The percentage of active pipelines without a named owner. As organizations scale, unmaintained pipelines accumulate. A mesh governance discipline should keep this near zero — every pipeline has an owner, and pipeline removal is a deliberate process.
Build a Modern Data Platform
For comprehensive guidance on data governance, lakehouse architecture, and agentic AI integration, pick up The 2026 Guide to Lakehouses, Apache Iceberg and Agentic AI: A Hands-On Practitioner's Guide to Modern Data Architecture, Open Table Formats, and Agentic AI.
Browse Alex's other data engineering and analytics books at books.alexmerced.com.
Dremio provides unified query access to your lakehouse data products with governance and performance. Try it free at dremio.com/get-started.