Designing Governed RAG on Data Products
Designing Governed RAG on Data Products
The first generation of enterprise RAG deployments had a serious trust problem. Organizations gave AI assistants access to the data warehouse — or to a vector store filled with documents scraped from internal wikis and Confluence — and discovered that the answers came back authoritative-sounding but frequently wrong, stale, or based on data the querying user wasn't supposed to see.
The "give the model warehouse access" approach conflates two separate problems: retrieval (finding relevant context) and governance (ensuring the retrieved context is accurate, fresh, and appropriate for the user). When these problems aren't separated architecturally, you get an AI system that confidently answers questions using data it shouldn't have accessed, or that retrieves stale snapshots from a document store that hasn't been updated in six months.
Governed RAG on data products separates these concerns. The retrieval layer enforces access policies before context reaches the model. Retrieved data comes from data products with defined SLAs and freshness guarantees, not from unstructured document dumps. And a semantic layer ensures that structured data queries generate consistent, policy-compliant SQL rather than ad-hoc queries that might bypass governance controls.
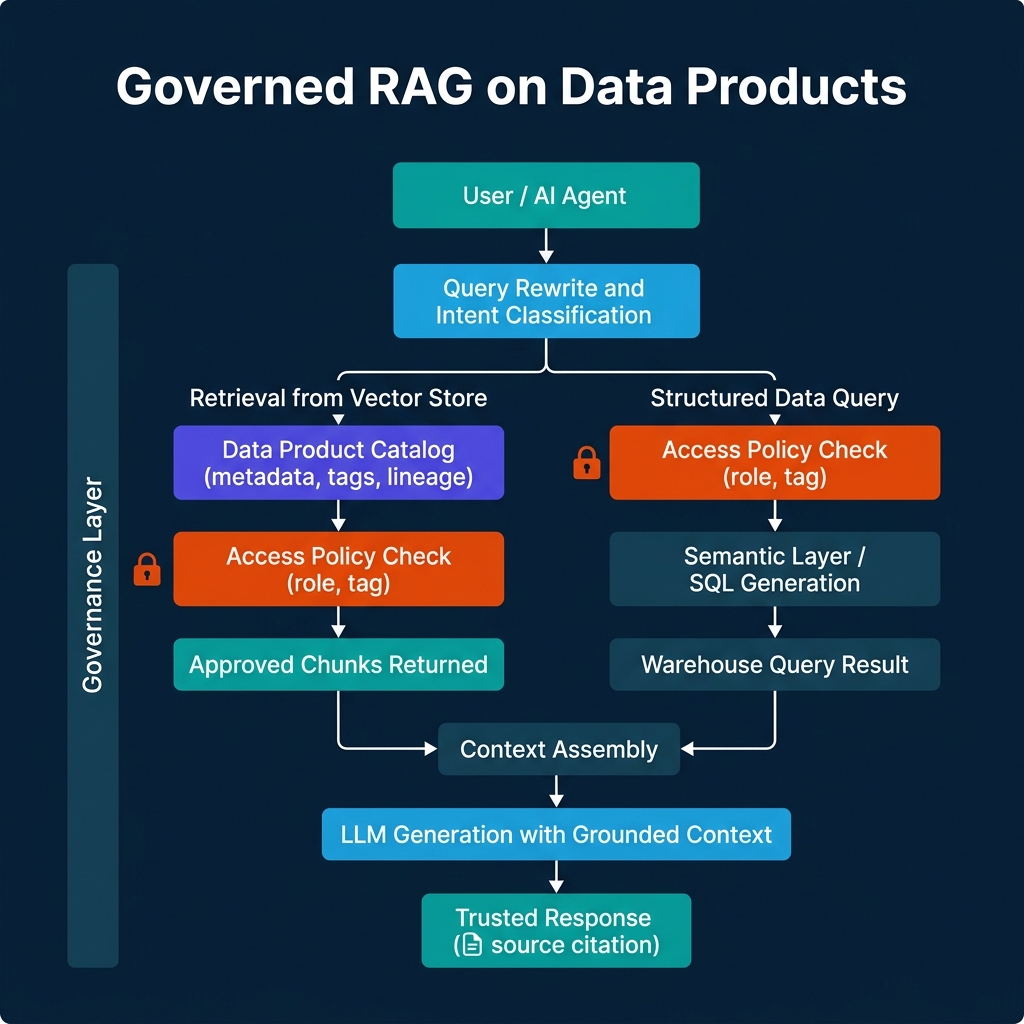
The Architecture
The architecture has three layers:
The retrieval layer handles unstructured context: documents, policies, runbooks, product documentation. It uses a vector store indexed from data products — governed, SLA-backed datasets — rather than open-ended document crawls. Access policies at the retrieval layer filter returned chunks to those the requesting user is authorized to see.
The structured query layer handles precise, quantitative questions that require SQL: "what was our revenue in Q1?", "how many active users do we have?", "what's the churn rate by region?". This layer routes through a semantic layer (dbt Semantic Layer, Snowflake Cortex Analyst, or similar) that generates deterministic SQL using governed metric definitions, not ad-hoc LLM-generated SQL against raw schema.
The governance layer enforces access control at both retrieval paths. A user asking about EMEA revenue who only has access to EMEA data gets EMEA metrics — not because the LLM magically knows the constraint, but because the policy check at the retrieval layer filtered the context and the row filter on the warehouse query enforced the regional restriction.
Data Products as Retrieval Sources
The fundamental governance improvement in governed RAG is sourcing retrieval context from data products rather than unstructured document stores.
A data product is a curated dataset published by a domain team with explicit quality contracts: a defined schema, documented ownership, SLAs for freshness and availability, and access controls. When your RAG system retrieves from data products, it retrieves from sources that have owners who are accountable for their accuracy, update on known schedules, and apply to documented policies.
Compare this to the alternative: a vector store populated by crawling internal wikis. Wiki documents have unknown freshness, no quality SLAs, no access control auditing, and no owner accountable for accuracy. When an AI assistant generates an answer from a two-year-old policy document that was superseded, nobody is responsible for that retrieval decision.
from langchain.vectorstores import Weaviate
from langchain.schema import Document
import weaviate
# Index only from governed data products with metadata
client = weaviate.Client("http://localhost:8080")
def index_data_product(
product_name: str,
version: str,
freshness_timestamp: str,
owner_team: str,
access_tags: list[str],
content_chunks: list[str],
embeddings: list[list[float]]
):
"""
Index a data product's content with governance metadata.
Access control enforced at query time using access_tags.
"""
for i, (chunk, embedding) in enumerate(zip(content_chunks, embeddings)):
client.data_object.create(
data_object={
"content": chunk,
"product_name": product_name,
"version": version,
"freshness_ts": freshness_timestamp,
"owner_team": owner_team,
"access_tags": access_tags # Used to filter at retrieval time
},
class_name="DataProductChunk",
vector=embedding
)Access Policy Enforcement at Retrieval
The access policy check happens before content reaches the LLM context window. A user with ANALYST role and EMEA regional access should retrieve only chunks tagged for their role and region. This is enforced in the vector store query filter, not in a prompt instruction to the LLM.
def retrieve_with_policy(
query_embedding: list[float],
user_role: str,
user_region: str,
k: int = 10
) -> list[dict]:
"""
Retrieve relevant chunks with access policy applied at query time.
Policy is enforced in the vector store query, not in the LLM prompt.
"""
# Policy-filtered retrieval: only return chunks the user can see
results = client.query.get(
"DataProductChunk",
["content", "product_name", "freshness_ts", "owner_team"]
).with_near_vector({
"vector": query_embedding
}).with_where({
"operator": "And",
"operands": [
{
"path": ["access_tags"],
"operator": "ContainsAny",
"valueText": [user_role, "PUBLIC", f"REGION_{user_region}"]
},
{
"path": ["freshness_ts"],
"operator": "GreaterThan",
"valueDate": "2025-01-01T00:00:00Z" # Freshness gate
}
]
}).with_limit(k).do()
return results["data"]["Get"]["DataProductChunk"]The freshness gate is particularly important. Stale context is a common source of AI assistant errors in enterprise settings. Setting a maximum staleness threshold at the retrieval layer ensures the model never generates answers from outdated data, even if the data product temporarily falls behind its SLA.
Routing Quantitative Questions Through the Semantic Layer
Questions that require precise calculation — revenue, user counts, conversion rates — should not be answered from retrieved document chunks. They should route to the semantic layer for deterministic SQL generation.
from openai import OpenAI
def classify_and_route(user_question: str, user_context: dict) -> dict:
"""
Classify the question and route to appropriate retrieval path.
Returns context assembled from the appropriate source.
"""
# Simple classification: metric questions vs knowledge questions
metric_keywords = ["revenue", "count", "rate", "percentage", "average", "total"]
is_metric_question = any(kw in user_question.lower() for kw in metric_keywords)
if is_metric_question:
# Route to semantic layer for deterministic SQL
sql = generate_metric_sql(
question=user_question,
user_region=user_context["region"],
user_role=user_context["role"]
)
return {"type": "structured", "sql": sql, "source": "semantic_layer"}
else:
# Route to vector retrieval from data products
chunks = retrieve_with_policy(
query_embedding=embed(user_question),
user_role=user_context["role"],
user_region=user_context["region"]
)
return {"type": "retrieval", "chunks": chunks, "source": "data_products"}Evaluating RAG Response Quality
Governed retrieval doesn't automatically produce good answers. The access policy filters ensure users only see authorized context, but they don't ensure the retrieved context is relevant or that the LLM uses it accurately. Evaluation tooling is necessary.
Key evaluation metrics for governed RAG pipelines:
Context relevance. For each retrieved chunk, how semantically similar is it to the question being answered? Low relevance scores indicate the vector index or filtering is returning technically authorized but topically off-target results.
Faithfulness. Does the LLM's generated answer accurately reflect the information in the retrieved chunks? Hallucination detection compares the generated claims against the retrieved context, flagging answers that assert information not present in the context.
Answer relevance. Is the generated answer actually responsive to the user's question? An answer that accurately summarizes retrieved context but doesn't address what was asked is technically faithful but practically useless.
MLflow 3's evaluation framework supports these metrics for RAG pipelines:
import mlflow
with mlflow.start_run():
eval_results = mlflow.evaluate(
model=governed_rag_pipeline,
data=eval_dataset,
model_type="question-answering",
evaluators=["default"],
extra_metrics=[
mlflow.metrics.genai.faithfulness(model="openai:/gpt-4o"),
mlflow.metrics.genai.relevance(model="openai:/gpt-4o"),
mlflow.metrics.genai.answer_correctness(model="openai:/gpt-4o")
]
)
mlflow.log_metric("avg_faithfulness", eval_results.metrics["faithfulness/v1/mean"])
mlflow.log_metric("avg_relevance", eval_results.metrics["relevance/v1/mean"])Snowflake Horizon AI Guardrails
Snowflake Horizon extends its governance framework to AI workloads through AI guardrails — policies that restrict what AI systems can access when using Cortex and AI-native features. For organizations using Snowflake as the data product backing for RAG, Horizon's AI guardrails add a policy layer limiting which subsets of authorized data can be included in AI context.
A sensitive financial table might be accessible to ANALYST role for SQL queries but excluded from AI context by guardrail policy — defense in depth that goes beyond standard role-based access.
-- Restrict AI access to non-PII columns
CREATE OR REPLACE AI USAGE POLICY restrict_ai_pii
BLOCK ENTITIES sensitive_columns_table
ON COLUMN email, phone, ssn;
ALTER TABLE customers
SET AI USAGE POLICY restrict_ai_pii;Building the Audit Trail
One of the underappreciated requirements of enterprise RAG is the audit trail. When a business decision is made based on an AI assistant's recommendation, auditors may need to know: what data did the AI see? What was retrieved for that specific query?
The governed RAG architecture enables this audit trail by design:
- Retrieval logs: Every vector store query, including filter conditions applied (role, region, freshness), logged with user identity and timestamp.
- Source attribution: Generated responses include citations to specific data product chunks retrieved, with version and freshness information.
- SQL query log: For structured queries routed to the semantic layer, generated SQL and warehouse execution plan are logged alongside the natural language question.
- LLM trace: MLflow tracing captures the full prompt, context, and response for each generation.
This four-layer audit trail satisfies most enterprise audit requirements — far more complete than what an ungoverned RAG system can provide.
Choosing Retrieval Infrastructure for Production
Vector store selection for governed RAG requires evaluating filtering capabilities alongside retrieval performance. Not every vector store implements the kind of metadata-filtered search required for access-controlled retrieval.
Weaviate supports filtering on arbitrary metadata fields at query time, making it a natural choice for governed RAG where access tags and freshness timestamps are part of the filter expression.
pgvector supports SQL WHERE clause filtering alongside similarity search, which makes access control filters natural extensions of existing PostgreSQL policy logic.
Milvus supports partition-based access control where different access tiers can be stored in different partitions, reducing filter overhead for large-scale deployments.
For most enterprise RAG deployments starting from scratch, the choice comes down to operational complexity tolerance. pgvector has the lowest operational overhead for teams already running PostgreSQL. Weaviate provides the richest native hybrid search and filter capabilities. Milvus provides the best scale-out path for deployments that expect to grow to billions of vectors.
Conclusion
Governed RAG on data products is the enterprise-grade version of retrieval-augmented generation. It's not the easiest path to a working demo — ungoverned RAG is faster to build. But it's the only version that produces responses an organization can trust, audit, and stand behind when someone asks how the AI came to a particular conclusion.
The key disciplines: source retrieval from data products with explicit ownership and freshness SLAs, enforce access policies at the retrieval layer (not in LLM prompts), route quantitative questions through a governed semantic layer, evaluate response quality against faithfulness and relevance metrics, and maintain a four-layer audit trail for accountability. This architecture makes AI assistants into reliable tools rather than plausible-sounding liability generators.
Chunking Strategy: The Hidden RAG Variable
Retrieval quality in RAG systems is heavily influenced by how documents are chunked before embedding. The chunking strategy determines the granularity of retrieval — too coarse, and the retrieved chunks contain irrelevant content that adds noise to the LLM prompt; too fine, and the chunks lack sufficient context for the LLM to reason effectively.
Fixed-size chunking divides documents into equal-length windows (e.g., 512 tokens) with optional overlap. It's simple but semantically arbitrary — a chunk boundary might fall in the middle of a sentence or concept.
Semantic chunking uses embedding similarity to detect natural breakpoints where the semantic content shifts. Chunks within the same section tend to have high cosine similarity; the similarity drops at section boundaries. This produces chunks that align with the document's conceptual structure rather than its character count.
Hierarchical chunking creates a two-level index: large parent chunks for broad context and small child chunks for precise retrieval. Retrieval uses the small chunks for semantic similarity search, but the LLM receives the full parent chunk as context. This preserves retrieval precision while giving the model adequate context window content.
For enterprise document corpora — policy documents, technical manuals, internal knowledge bases — hierarchical chunking consistently outperforms fixed-size chunking on faithfulness metrics. The implementation requires storing parent-child chunk relationships in the vector store metadata:
def hierarchical_chunk(document: str, parent_size: int = 1500, child_size: int = 300) -> list[dict]:
"""
Create hierarchical chunks with parent-child relationships.
Returns a list of chunk records with parent references.
"""
chunks = []
parent_id = 0
# Create parent chunks
parent_windows = create_fixed_windows(document, parent_size, overlap=150)
for parent_text in parent_windows:
# Create child chunks from each parent
child_windows = create_fixed_windows(parent_text, child_size, overlap=50)
for child_text in child_windows:
chunks.append({
"text": child_text,
"parent_text": parent_text,
"parent_id": parent_id,
"embedding": embed_text(child_text), # Child embedding for retrieval
})
parent_id += 1
return chunksAt retrieval time, search returns child chunks, but the LLM receives the full parent text from the parent_text field.
Context Window Management
Enterprise LLM deployments face a constraint that research demos ignore: the context window has a finite size. Claude 3.5 Sonnet supports 200K tokens; GPT-4o supports 128K. These seem large, but a RAG system that retrieves 10 chunks of 1500 tokens each, plus conversation history, plus the system prompt, plus structured data from the semantic layer can easily approach or exceed the limit.
Context window budget management requires explicitly tracking what goes into the prompt:
def build_governed_rag_prompt(
query: str,
retrieved_chunks: list[dict],
structured_data: dict | None,
conversation_history: list[dict],
max_context_tokens: int = 80_000 # Conservative budget below model limit
) -> str:
"""
Build a prompt that fits within the context window budget.
Prioritizes: system prompt > structured data > relevant chunks > history
"""
system_prompt = load_system_prompt()
system_tokens = count_tokens(system_prompt)
# Reserve budget for response
response_budget = 4_000
available = max_context_tokens - system_tokens - response_budget
# Structured data is highest priority (exact facts)
structured_section = format_structured_data(structured_data) if structured_data else ""
available -= count_tokens(structured_section)
# History (most recent first, truncated to available budget)
history_section = truncate_history_to_budget(conversation_history, available // 3)
available -= count_tokens(history_section)
# Fill remaining budget with retrieved chunks (most relevant first)
chunks_section = fill_chunks_to_budget(retrieved_chunks, available)
return f"{system_prompt}\n\n{structured_section}\n\n{chunks_section}\n\n{history_section}\n\nQuestion: {query}"This explicit budget management prevents context overflow while ensuring the most reliable content (structured semantic layer data) gets priority over less reliable content (unstructured retrieved chunks).
The Dual-Pipeline Architecture for Production RAG
Production RAG systems serving enterprise users typically benefit from separating the retrieval and generation concerns into independent scaling dimensions. A query routing layer directs different question types to different backends:
- Quantitative questions → Semantic layer SQL generation → Database execution → Structured result formatting
- Qualitative questions about policies, procedures, documentation → Vector retrieval → LLM generation with retrieved context
- Mixed questions → Both pipelines in parallel → LLM synthesis combining structured data and retrieved text
This dual-pipeline design means the vector store and the SQL execution engine scale independently. When the volume of quantitative queries grows (because more users are asking "what's my team's budget status this quarter"), compute scales on the SQL path. When document corpus grows, storage and indexing scales on the vector path.
The routing logic is itself a classification model — either a fine-tuned classifier or a smaller, fast LLM that categorizes the incoming question before routing:
def route_query(query: str) -> str:
"""Returns 'structured', 'unstructured', or 'hybrid'"""
classifier = load_query_classifier()
return classifier.predict(query)
def answer_question(query: str, user_context: dict) -> dict:
route = route_query(query)
if route == "structured":
sql = generate_governed_sql(query, user_context)
result = execute_against_semantic_layer(sql)
return format_structured_response(result, query)
elif route == "unstructured":
chunks = retrieve_with_access_control(query, user_context)
return generate_rag_response(query, chunks)
else: # hybrid
sql = generate_governed_sql(query, user_context)
structured = execute_against_semantic_layer(sql)
chunks = retrieve_with_access_control(query, user_context)
return generate_hybrid_response(query, structured, chunks)The dual-pipeline architecture adds implementation complexity but significantly improves answer quality for mixed enterprise use cases where questions range from precise metric lookups to open-ended policy questions.
Build AI-Ready Data Platforms
For comprehensive guidance on agentic AI integration with lakehouse data architecture, pick up The 2026 Guide to Lakehouses, Apache Iceberg and Agentic AI: A Hands-On Practitioner's Guide to Modern Data Architecture, Open Table Formats, and Agentic AI.
Browse Alex's other data engineering and analytics books at books.alexmerced.com.
Dremio provides governed multi-engine query access to your Iceberg lakehouse, making it an ideal data product foundation for enterprise RAG. Try it free at dremio.com/get-started.